本文演示在spring boot 中引入tika的方式解析文档。如下:
引入依赖
在spring boot 项目中引入如下依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-bom</artifactId>
<version>2.8.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
</dependency>
创建配置
-
将tika-config.xml文件放在resources目录下。tika-config.xml文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<encodingDetectors>
<encodingDetector class="org.apache.tika.parser.html.HtmlEncodingDetector">
<params>
<param name="markLimit" type="int">64000</param>
</params>
</encodingDetector>
<encodingDetector class="org.apache.tika.parser.txt.UniversalEncodingDetector">
<params>
<param name="markLimit" type="int">64001</param>
</params>
</encodingDetector>
<encodingDetector class="org.apache.tika.parser.txt.Icu4jEncodingDetector">
<params>
<param name="markLimit" type="int">64002</param>
</params>
</encodingDetector>
</encodingDetectors>
</properties>
-
创建配置类MyTikaConfig import java.io.IOException; import java.io.InputStream; import org.apache.tika.Tika; import org.apache.tika.config.TikaConfig; import org.apache.tika.detect.Detector; import org.apache.tika.exception.TikaException; import org.apache.tika.parser.AutoDetectParser; import org.apache.tika.parser.Parser; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.Resource; import org.springframework.core.io.ResourceLoader; import org.xml.sax.SAXException; /** * tika配置类 */ @Configuration public class MyTikaConfig { @Autowired private ResourceLoader resourceLoader; @Bean public Tika tika() throws TikaException, IOException, SAXException { Resource resource = resourceLoader.getResource("classpath:tika-config.xml"); InputStream inputStream = resource.getInputStream(); TikaConfig config = new TikaConfig(inputStream); Detector detector = config.getDetector(); Parser autoDetectParser = new AutoDetectParser(config); return new Tika(detector, autoDetectParser); } }
在项目使用
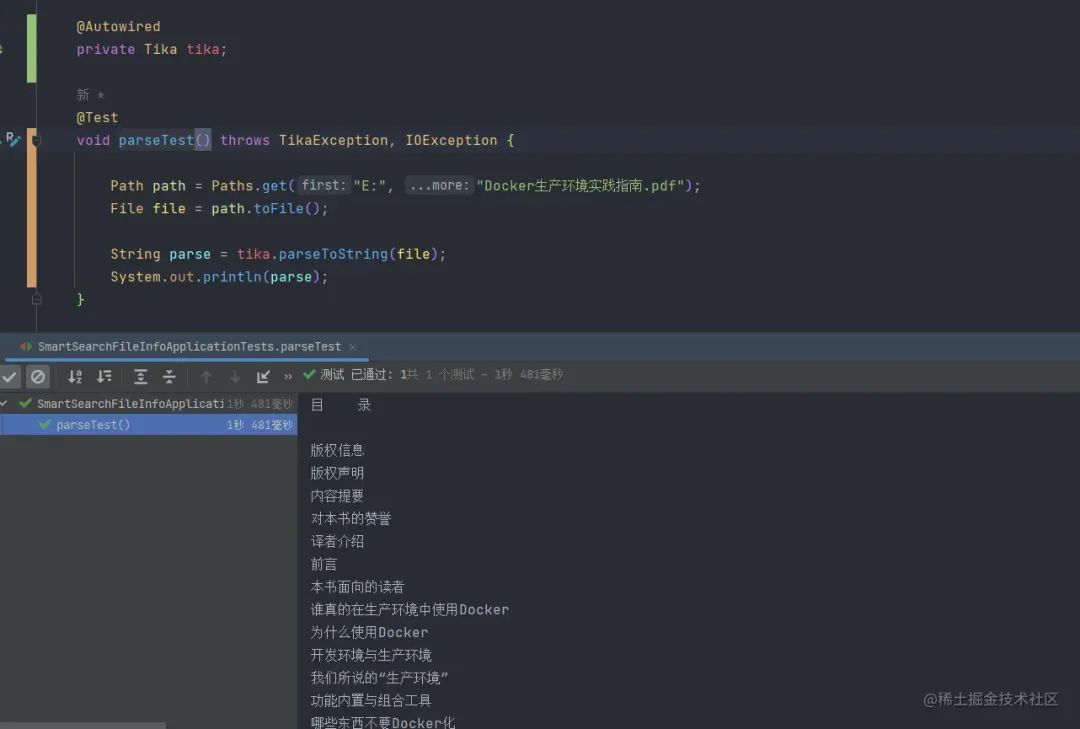
作者:不可食用盐
链接:https://juejin.cn/post/7252159509848899640
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。侵权投诉:375170667@qq.com