深度解析JDK序列化原理及Fury高度兼容的极致性能实现
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
java.io.ObjectOutputStream.PutField fields = s.putFields();
fields.put("rnd", U.getLong(Thread.currentThread(), SEED));
fields.put("initialized", true);
s.writeFields();
}
反序列化整体流程
public static class CustomReplaceClass implements Serializable {
Object writeReplace() {
return new CustomReplaceClass();
}
Object readResolve() {
return new CustomReplaceClass();
}
}
Exception in thread "main" java.lang.StackOverflowError
at java.base/java.lang.reflect.InvocationTargetException.<init>(InvocationTargetException.java:73)
at jdk.internal.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at com.caucho.hessian.io.WriteReplaceSerializer.writeReplace(WriteReplaceSerializer.java:184)
at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:155)
at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465)
at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:167)
at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465)
at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:167)
at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465)
at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:167)
at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465)
/**
* Head of linked list.
* Invariant: head.item == null
*/
transient Node<E> head;
/**
* Tail of linked list.
* Invariant: last.next == null
*/
private transient Node<E> last;
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
fullyLock();
try {
// Write out any hidden stuff, plus capacity
s.defaultWriteObject();
// Write out all elements in the proper order.
for (Node<E> p = head.next; p != null; p = p.next)
s.writeObject(p.item);
// Use trailing null as sentinel
s.writeObject(null);
} finally {
fullyUnlock();
}
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
readHolds = new ThreadLocalHoldCounter();
setState(0); // reset to unlocked state
}
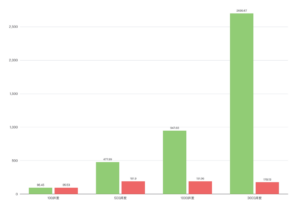
Kryo存在的问题
- JDK序列化性能很差,导致kryo序列化性能大幅退化
- JDK序列化结果很大,导致kryo序列化数据膨胀
- 转发给JDK序列化的对象子图不会跟Kryo share同一个引用表,如果该子图共享/循环引用了其它对象,则会出现重复序列化/递归栈溢出
kryo不支持父子类出现重名字段,这在某些条件下也会成为一个使用限制。
- Jsonb不支持任何JDK自定义序列化方法,反序列化会报错
-
Fst不支持类型前后兼容,无法在服务化场景使用
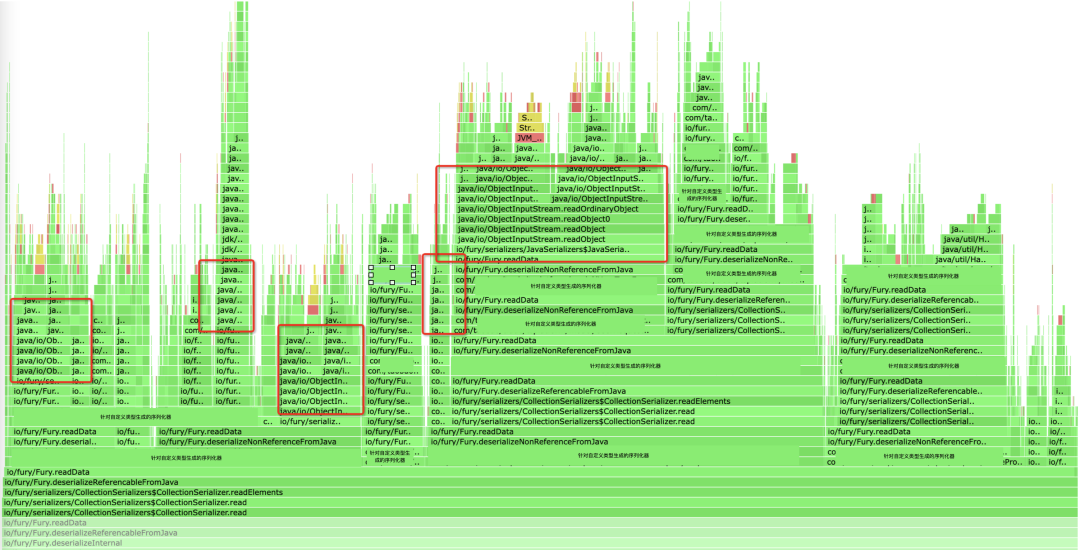
早期序列化流程
整体实现在:
io.fury.serializers.ReplaceResolveSerializer和
io.fury.serializers.ObjectStreamSerializer
ReplaceResolveSerializer
ObjectStreamSerializer
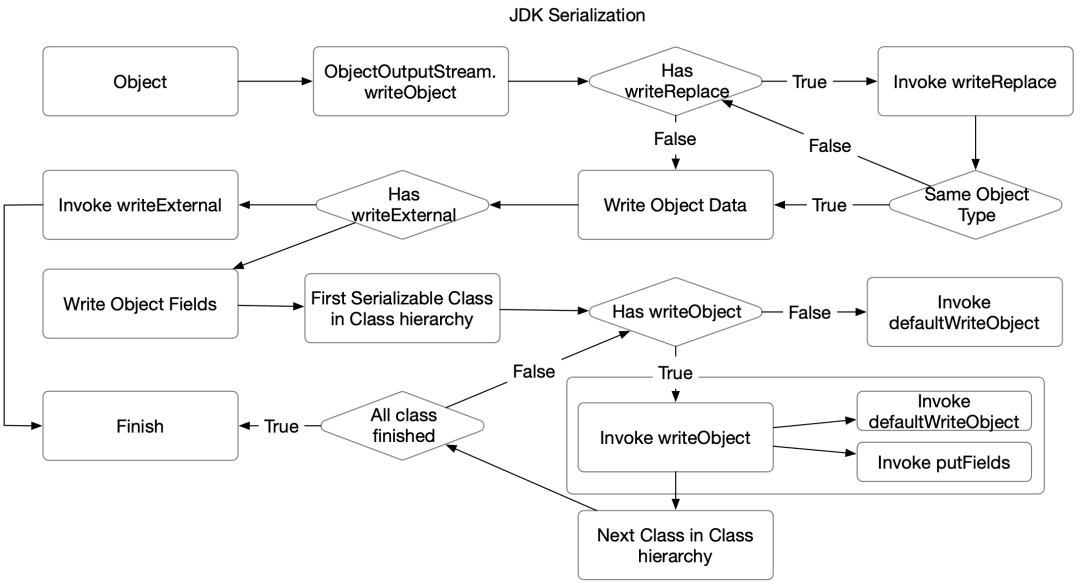
ObjectStreamSerializer实现了整套:
JDK writeObject/readObject/readObjectNoData/registerValidation
行为,保证行为跟JDK的一致性,在任意情况下序列化都不会报错。
由于用户在:
writeObject/readObject/ readObjectNoData/registerValidation
里面调用的是:
JDK ObjectOutputStream/ObjectInputStream /PutField/GetField的接口
因此Fury也实现了一套:
ObjectOutputStream/ObjectInputStream/PutField/ GetField
的子类,保证实际序列化逻辑可以转发给Fury。
为了保证类型前后兼容,同时保证:
defaultWriteObject/defaultReadObject
创建JITCompatibleSerializer进行序列化。
序列化器初始化部分
-
获取无参数构造函数或者第一个Non Serializable父类无参数构造函数。为了避免JDK17以上版本的反射访问权限问题,在JDK17以上版本会通过Unsafe直接获取ObjectStreamClass.lookup(type)抽取的构造函数。 Constructor constructor; try { constructor = type.getConstructor(); if (!constructor.isAccessible()) { constructor.setAccessible(true); } } catch (Exception e) { constructor = (Constructor) ReflectionUtils.getObjectFieldValue(ObjectStreamClass.lookup(type), "cons"); }
-
遍历对象层次结构,创建每个class的JITCompatibleSerializer/CompatibleSerializer/ FuryObjectOutputStream/FuryObjectInputStream等。其中slotsSerializer是JITCompatibleSerializer,用于执行ObjectOutputStream#defaultWriteObject/ObjectInputStream#defaultReadObject。compatibleStreamSerializer用于序列化将PutFields设置的字段,因为PutFields设置的字段可能在当前对象类型里面不存在,因此这种情况下无法使用JIT进行类型推断和序列化。
List<SlotsInfo> slotsInfoList = new ArrayList<>();
Class<?> end = type;
// locate closest non-serializable superclass
while (end != null && Serializable.class.isAssignableFrom(end)) {
end = end.getSuperclass();
}
while (type != end) {
slotsInfoList.add(new SlotsInfo(fury, type));
type = type.getSuperclass();
}
Collections.reverse(slotsInfoList);
slotsInfos = slotsInfoList.toArray(new SlotsInfo[0]);
private static class SlotsInfo {
private final Class<?> cls;
private final Method writeObjectMethod;
private final Method readObjectMethod;
private final Method readObjectNoData;
private final CompatibleSerializerBase slotsSerializer;
private final ObjectIntMap<String> fieldIndexMap;
private final FieldResolver putFieldsResolver;
private final CompatibleSerializer compatibleStreamSerializer;
private final FuryObjectOutputStream objectOutputStream;
private final FuryObjectInputStream objectInputStream;
private final ObjectArray getFieldPool;
}
序列化器执行部分
- 序列化执行部分
-
- 写入所有Serializable class数量
- 遍历对象类层次结构,依次序列化每个类型的字段数据。序列化每个类型的数据分为以下几个部分:
- 如果当前对象所在类型没有定义writeObject方法,则直接调用slotsSerializer (JITCompatibleSerializer)序列化当前类型所有字段。
- 如果前对象所在类型定义了writeObject方法,则会缓存之前一次序列化的上下文,然后调用writeObject方法,传入Fury实现的FuryObjectOutputStream。
-
在FuryObjectOutputStream里面,同时也会针对putFields/writeFields/defaultWriteObject进行特殊的处理。putFields/writeFields会把对象转换成CompatibleSerializer可识别的array形式,defaultWriteObject则会直接调用slotsSerializer (JITCompatibleSerializer)序列化当前类型所有字段。
for (SlotsInfo slotsInfo : slotsInfos) {
buffer.writeShort((short) slotsInfos.length);
classResolver.writeClassInternal(buffer, slotsInfo.cls);
Method writeObjectMethod = slotsInfo.writeObjectMethod;
if (writeObjectMethod == null) {
slotsInfo.slotsSerializer.write(buffer, value);
} else {
FuryObjectOutputStream objectOutputStream = slotsInfo.objectOutputStream;
Object oldObject = objectOutputStream.targetObject;
MemoryBuffer oldBuffer = objectOutputStream.buffer;
FuryObjectOutputStream.PutFieldImpl oldPutField = objectOutputStream.curPut;
boolean fieldsWritten = objectOutputStream.fieldsWritten;
try {
objectOutputStream.targetObject = value;
objectOutputStream.buffer = buffer;
objectOutputStream.curPut = null;
objectOutputStream.fieldsWritten = false;
writeObjectMethod.invoke(value, objectOutputStream);
} finally {
objectOutputStream.targetObject = oldObject;
objectOutputStream.buffer = oldBuffer;
objectOutputStream.curPut = oldPutField;
objectOutputStream.fieldsWritten = fieldsWritten;
}
}
}
- 根据构造函数创建对象实例。
- 将对象实例写入引用表。
- 读取对象层次结构所有Serializable Class数量。
- 依次从数据读取class,并和当前类型层次结构的class进行比较。如果不一致,则代表当前类型层次结构发生了变化,引入了新的父类,如果该类型定义了readObjectNoData,则调用该方法进行初始化,然后向上遍历类型层次结构,直到找到相同类型。
- 反序列化该类型的所有字段值并设置到对象字段上面。
-
- 如果对象没有定义readObject方法,则直接调用slotsSerializer (JITCompatibleSerializer)进行反序列化。
- 如果定义了readObject方法,则调用对象的readObject方法,传入Fury实现的FuryObjectInputStream。
- 在FuryObjectInputStream里面,同时也会针对readFields/defaultReadObject进行特殊的处理。readFields会使用CompatibleSerializer把对象转换成可识别的GetField形式,defaultReadObject则会直接调用slotsSerializer (JITCompatibleSerializer)反序列化当前类型所有字段。
- 如果在readObject期间用户通过registerValidation注册了ObjectInputValidation回调,则会在返回该对象之前,按照优先级依次执行回调。
- 至此反序列化完成。核心代码大致如下:
Object obj = null;
if (constructor != null) {
try {
obj = constructor.newInstance();
} catch (InstantiationException | IllegalAccessException | InvocationTargetException e) {
Platform.throwException(e);
}
} else {
obj = Platform.newInstance(type);
}
fury.getReferenceResolver().reference(obj);
int numClasses = buffer.readShort();
int slotIndex = 0;
TreeMap<Integer, ObjectInputValidation> callbacks = new TreeMap<>(Collections.reverseOrder());
for (int i = 0; i < numClasses; i++) {
Class<?> currentClass = classResolver.readClassInternal(buffer);
SlotsInfo slotsInfo = slotsInfos[slotIndex++];
while (currentClass != slotsInfo.cls) {
// the receiver's version extends classes that are not extended by the sender's version.
Method readObjectNoData = slotsInfo.readObjectNoData;
if (readObjectNoData != null) {
readObjectNoData.invoke(obj);
}
slotsInfo = slotsInfos[slotIndex++];
}
Method readObjectMethod = slotsInfo.readObjectMethod;
if (readObjectMethod == null) {
slotsInfo.slotsSerializer.readAndSetFields(buffer, obj);
} else {
FuryObjectInputStream objectInputStream = slotsInfo.objectInputStream;
MemoryBuffer oldBuffer = objectInputStream.buffer;
Object oldObject = objectInputStream.targetObject;
FuryObjectInputStream.GetFieldImpl oldGetField = objectInputStream.getField;
FuryObjectInputStream.GetFieldImpl getField =
(FuryObjectInputStream.GetFieldImpl) slotsInfo.getFieldPool.popOrNull();
if (getField == null) {
getField = new FuryObjectInputStream.GetFieldImpl(slotsInfo);
}
boolean fieldsRead = objectInputStream.fieldsRead;
try {
objectInputStream.fieldsRead = false;
objectInputStream.buffer = buffer;
objectInputStream.targetObject = obj;
objectInputStream.getField = getField;
objectInputStream.callbacks = callbacks;
readObjectMethod.invoke(obj, objectInputStream);
} finally {
objectInputStream.fieldsRead = fieldsRead;
objectInputStream.buffer = oldBuffer;
objectInputStream.targetObject = oldObject;
objectInputStream.getField = oldGetField;
slotsInfo.getFieldPool.add(getField);
objectInputStream.callbacks = null;
Arrays.fill(getField.vals, FuryObjectInputStream.NO_VALUE_STUB);
}
}
}
for (ObjectInputValidation validation : callbacks.values()) {
validation.validateObject();
}
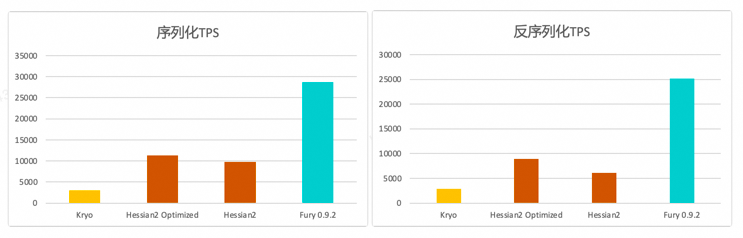
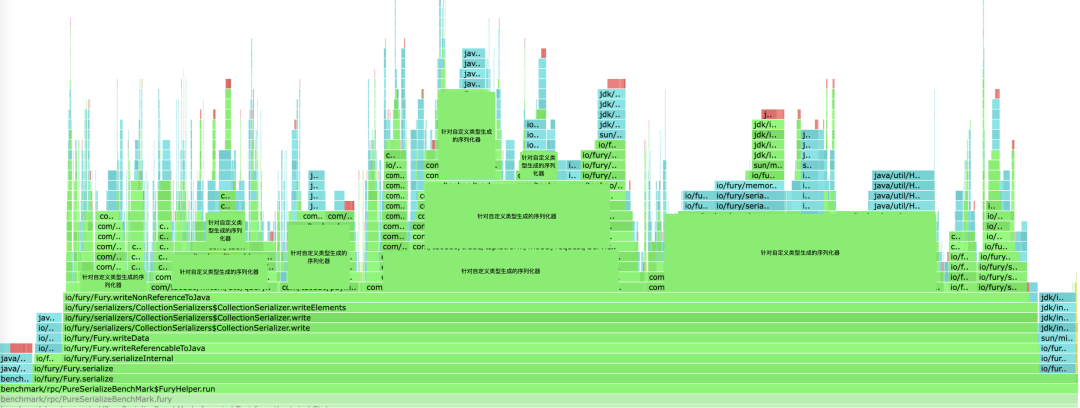
[1]writeObject:https://docs.oracle.com/en/java/javase/18/docs/specs/serialization/output.html#the-writeobject-method
[2]readObject:
https://docs.oracle.com/en/java/javase/18/docs/specs/serialization/input.html#the-readobject-method
[3]writeReplace:
https://docs.oracle.com/en/java/javase/18/docs/specs/serialization/output.html#the-writereplace-method
[4]readResolve:https://docs.oracle.com/en/java/javase/18/docs/specs/serialization/input.html#the-readresolve-method
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包