分布式缓存全面详解
缓存是提高服务性能的一把利剑,尤其在高并发、高请求量的服务中性能提升明显。如果后端服务只靠关系型数据库提供支撑,系统会很快达到处理瓶颈。缓存设计无处不在,通常来说可以分为本地缓存与分布式缓存。本地缓存框架主要有Guava cache、Caffeine等,它们利用本地服务器内存来存储接口的返回数据。本地缓存有一定的局限性,多个进程间不能共享缓存,且缓存都是单机保存不容易扩展,本地机器宕机后缓存不能持久化。相对于本地缓存,分布式缓存可以解决本地缓存存在的问题,缓存数据集中存储并可以被后端服务共享访问,对于缓存数据还可以进行副本存储,做到持久化存储。不过引入分布式缓存也会带来一些运维成本,还有数据不一致等问题。总体来说,分布式缓存可以提高服务性能,减少后端服务的压力,收益大于成本。通常分布式缓存组件有Redis、Couchbase等本节主要以Redis组件介绍为主。
Redis是一个开源的、基于内存的Key-Value缓存数据库。Redis因其丰富的数据类型、高性能I/O、串行执行命令、数据持久化等特性而流行开来,Redis非常适合做分布式缓存数据库。Redis有5种基本数据类型:
lString:字符串类型,是Redis中最常用的数据类型。Key与Value都有一定的大小限制,如果太大会影响性能。字符串类型通常可以保存sessionId等信息,在计算器、分布式锁、全局ID等这类场景中使用。
lHash:哈希类型,类似JAVA中的HashMap这种数据结构。哈希类型的底层数据结构有ziplist和hashtable,当哈希类型元素个数小于配置限制以及值小于配置的限制时采用ziplist结构,否则使用hashtable结构。哈希类型通常可以保存一些配置信息,例如某个活动ID下的配置信息等。
lList:列表类型,底层包括两种实现:ziplist与linkedlist。列表类型通常用作消息队列来使用。
lSet:集合类型,底层实现是intset或hashtable。集合中元素不能重复,通常用作一类数据的集合来存储,例如社交媒体关注的“大V”集合等。
lSorted set:有序集合,底层实现包括ziplist或skiplist。有序集合常用场景主要是在有排序需求的地方,例如按销量排序的商品、热搜榜等。
其他数据类型包括:
lBitmap:位图类型,主要按位存储,可以按位进行计算。位图非常类似BloomFilter,可以判断某个值是否存在这种使用场景。
lHyperloglog:HyperLogLog主要的应用场景就是进行基数统计。
lGeo:主要存储地理位置信息数据。
了解了Redis的一些数据结构类型,针对具体的场景选用不同的数据类型来使用。Redis虽然基于内存存储数据,但是也有持久化机制,将缓存数据持久化到磁盘上。Redis有两种持久化机制:RDB(Redis DataBase)和AOF(Append Only File)。RDB是每隔一定时间对Redis进行快照然后存储下来。AOF是将Redis的执行命令存储下来。相对来说RDB恢复数据更快,但是会丢失一定时间内的数据。AOF只会丢失最后执行的几条执行命令,所以恢复的数据更全一些。当然新的版本已经有RDB和AOF两种混合的持久化方式。
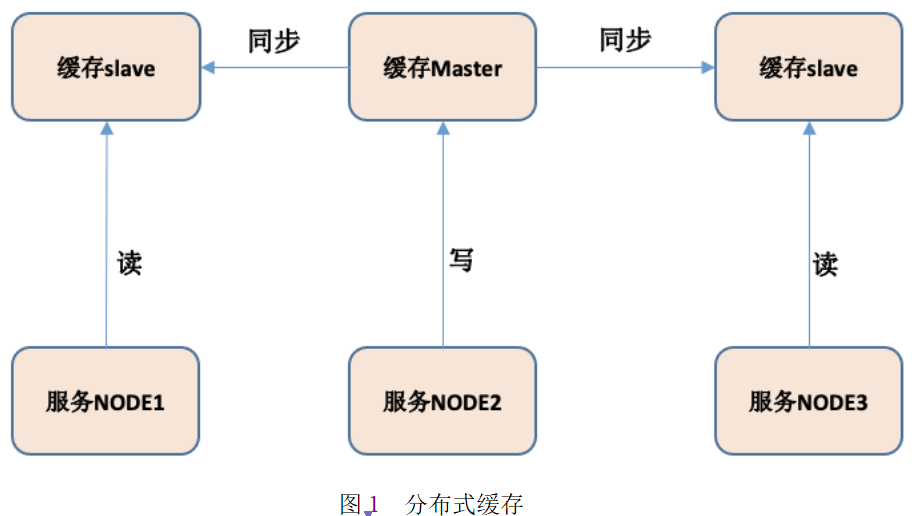
Redis的在生产环境部署通常有几种模式:主从模式、哨兵模式以及集群模式。主从模式可以是一主多从,写缓存通过主库来操作,从库同步主库的数据并用来读取数据。哨兵模式是为了高可用,监控主库,当主库挂掉的时候,在从库中选择一个节点变为主库,这样避免了主库宕机不用使用的情况。Redis为了更好的扩展,提供了分片模式,设置了16384个槽,对缓存key进行hash计算,根据hash值分配到不同的槽与分片节点上。
Spring Boot提供了对Redis的集成,提供了RedisTemplate类,完成Redis命令的执行,自动配置RedisTemplate代码如下:
public class RedisCacheConfiguration {/*** 配置Redis连接工厂*/public JedisConnectionFactory getJedisConnectionFactory(RedisConfigProperties redisConfigProperties) {JedisConnectionFactory jedisConnectionFactory = null;try {RedisStandaloneConfiguration redisStandaloneConfiguration = new RedisStandaloneConfiguration(redisConfigProperties.getHost(),redisConfigProperties.getPort());redisStandaloneConfiguration.setPassword(redisConfigProperties.getPassword());redisStandaloneConfiguration.setDatabase(redisConfigProperties.getDatabase());jedisConnectionFactory = new JedisConnectionFactory(redisStandaloneConfiguration);jedisConnectionFactory.getPoolConfig().setMaxTotal(50);jedisConnectionFactory.getPoolConfig().setMaxIdle(50);jedisConnectionFactory.getPoolConfig().setMaxWaitMillis(redisConfigProperties.getTimeout());} catch (RedisConnectionFailureException e) {e.getMessage();}return jedisConnectionFactory;}(name = "redisTemplate")public RedisTemplate<String, Object> redisTemplate(JedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper objectMapper = new ObjectMapper();objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);redisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.afterPropertiesSet();return redisTemplate;}}
当数据更新的时候,需要同步更新缓存。缓存长时间没有更新,可以采用过期策略进行管理。总之,缓存是有生命周期的。缓存的更新策略是为了保证缓存数据与真实数据保持一致。但是现实中,始终存在时间差,会造成数据不一致的问题。如图1所示:
缓存是通过内存空间来换取响应时间,但内存是昂贵的,所以当缓存容量达到一定量级时需要删除缓存数据。通常分布式缓存的过期策略通常包括以下几种:
lLRU(Least Recently Used):最近很长时间没有被使用的缓存会被删除。
lLFU(Less Frequently Used):最近访问次数最少的会被删除。
lFIFO(First In First Out):先进先出原则,最先进入的会被删除。
Redis本身也有六种内存淘汰策略:
lnoeviction:不删除缓存,当达到内存限制时,会引发报错。
lallkeys-lru:所有key采用LRU淘汰策略。
lvolatile-lru:对于设置了过期时间的key采用LRU淘汰策略。
lallkeys-random:对于所有key采用随机淘汰的策略。
lvolatile-random:对于设置了过期时间的key随机删除。
lvolatile-ttl:在设置了过期时间的key中,删除剩余时间短的那部分。
Redis可以对key进行设置过期时间,它的过期策略有两种:
l定期删除:Redis间隔一定时间,检查设置了过期时间的key,如果这些key过期了则删除。
l惰性删除:在获取key的时候,先检测一下这个key是否设置了过期时间,是否已经过期,如果是则不返回。
通常分布式缓存更新策略有以下几种:
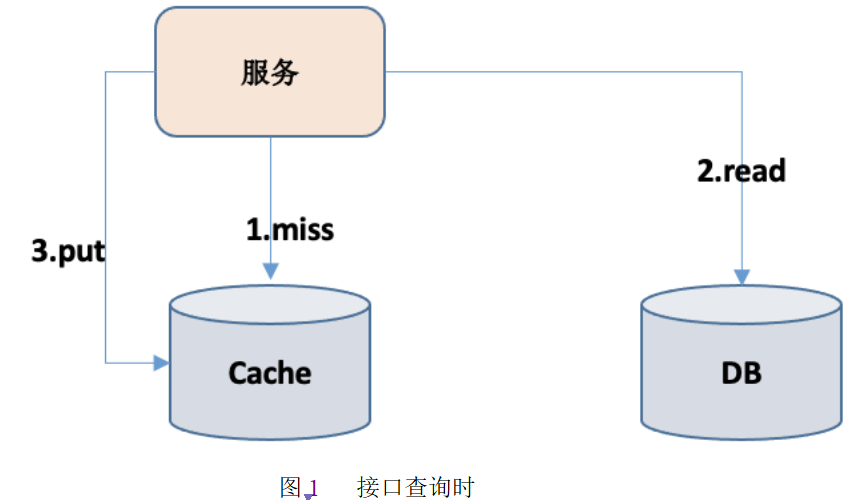
Cache aside:接口查询时,首先查询缓存数据,如果有则返回,如果没有,则查询数据库,然后存储到缓存中。接口更新时,先修改数据,然后直接删除缓存。如图1、图2所示:
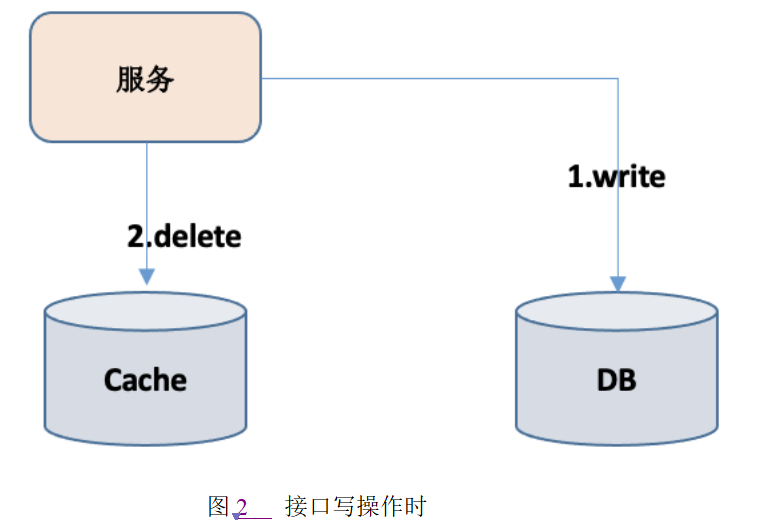
lRead/Write through:缓存的操作逻辑由缓存代理来管理。
lWrite Behind Caching Pattern:异步处理缓存,先更新缓存然后异步更新数据库。
引入缓存会造成数据不一致的问题,下面看看两种情况下的数据不一致情况,一种是并发读写会造成数据不一致,另一种是主从同步延迟造成的数据不一致。
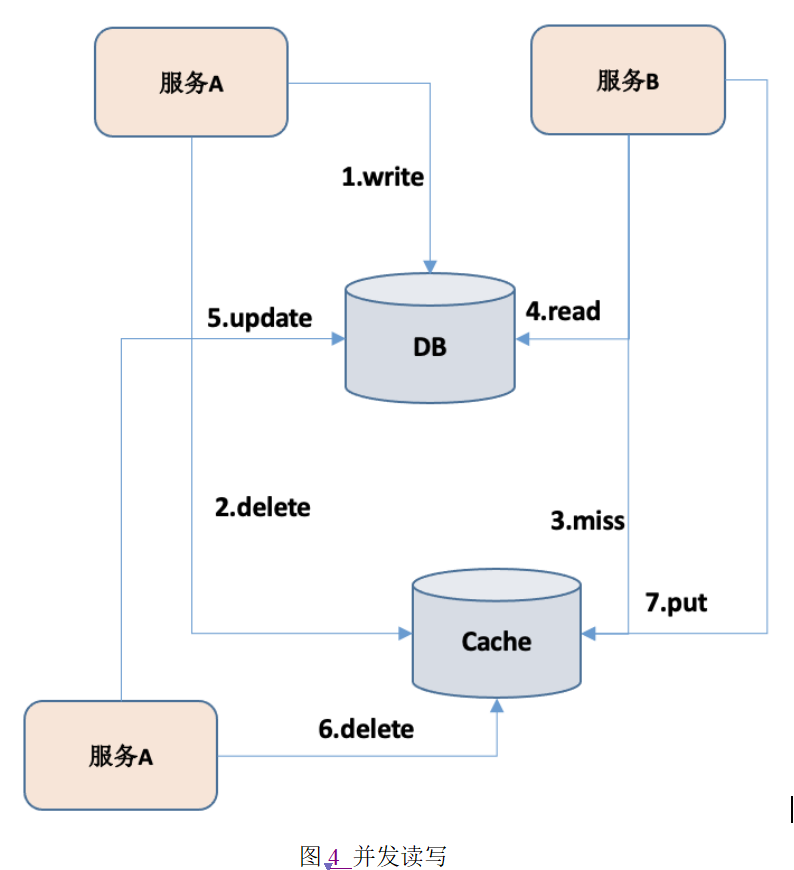
如图4所示,展示并发读写会造成数据不一致的情况。当服务A写入数据后,删除缓存,此时服务B读取数据,发现缓存失效,然后去数据库取数据,此时还未写入缓存,服务A又开始写入数据,并删除缓存,之后服务B写入之前数据到缓存,这样就造成的数据不一致的情况。缓存的数据与最新的数据库数据不一致。
另一种是数据库主从同步导致不一致的情况,如图5所示:
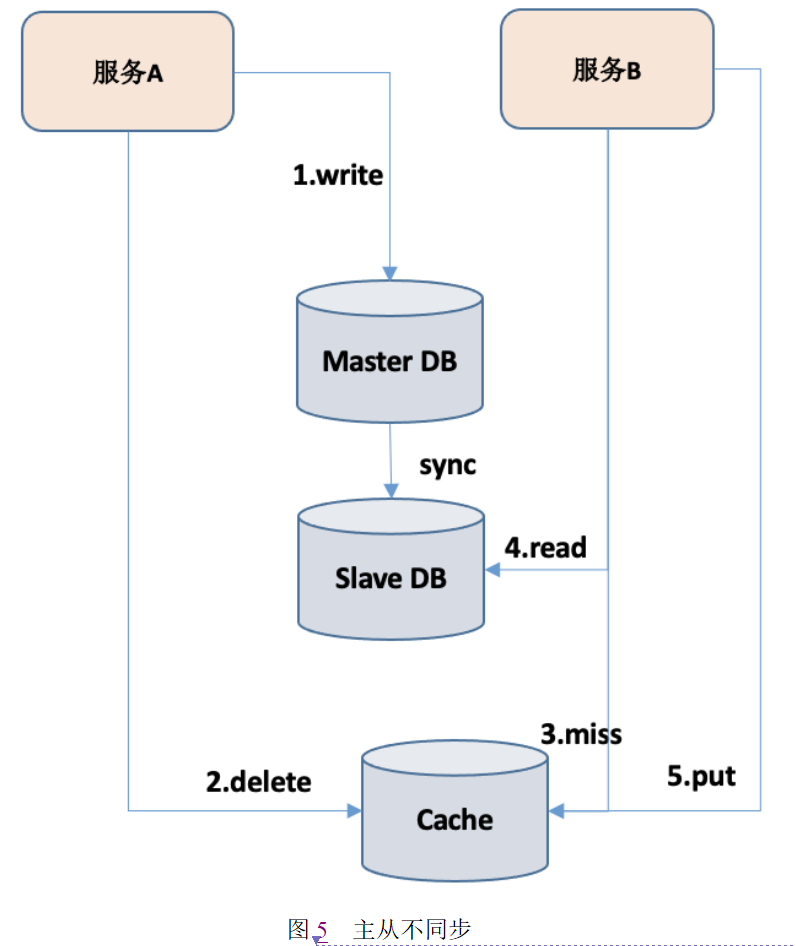
当服务读写分离的时候,由于主库同步到从库的时间慢,从而导致写入缓存的数据还是从库的,这样就导致了数据不一致情况。
针对并发读写的情况,可以采用分布式锁的机制,在一次写数据并删除缓存操作时进行加锁,其他线程不能访问,这种串行化的方式解决。还可以使用延迟双删的策略,如果主从不同步,可以设置延迟时间再删一次,把从库的数据缓存删除。还可以采用异步删除的机制,通过数据库的操作记录,发送消息,通过消息组件然后消费处理缓存。总之,针对不同的应用场景,使用不同的策略来达到数据一致性。
一个良好的分布式缓存设计可以抵挡大部分的请求,但是当缓存突然失效,大量请求就会穿透到后端数据库,短时间内大量并发请求有可能使数据库内存或CPU飙升,最终造成服务不可用。所以,在使用分布式缓存时需要考虑这些问题。下面主要从三个场景进行描述缓存失效问题:缓存穿透、缓存击穿、缓存雪崩。
l缓存穿透:当请求的数据不在缓存中,同时数据库中也不存在。这样每次请求都会打到后端数据库,造成数据库承受大量请求,有可能会打满数据库连接造成不可用的情况。针对这种情况,一个解决方案可以直接缓存一个null值,来抵挡请求到后端数据库。另一个是,可以构建一个布隆过滤器,先判断数据是否在布隆过滤器中,没有命中可以直接返回空。
l缓存击穿:缓存击穿是当一个key失效后,大量请求并发访问后端数据库,造成数据库瞬间访问压力增大,有可能崩溃的情况。这种情况,通常是访问一个热key,当热key失效时大量请求被打到后端数据库。针对热key的情况,一种方案是不设置过期时间。另一种方案可以针对这种接口进行限流或加锁,限制请求大量的穿透到后端数据库。
l缓存雪崩:当缓存数据在某一时刻大批量的失效,所有请求穿透到后端数据库,导致数据库宕机,最终服务不可用。一般当缓存服务宕机或扩容时会发生。针对这种情况,首先需要对缓存服务进行高可用配置,扩容时做好分片处理,还有对请求进行限流。
引入缓存需要考虑数据不一致的问题,如果服务需要强一致性的话,则不能使用分布式缓存。所以,在使用分布式缓存的时候,需要根据具体的场景指定更新策略。如果比较重要的服务,又不想出现服务不可能的情景,则需要进行一些热key预加载,通过统计缓存的命中情况与使用率,扫描出热key,在服务启动时或单独使用缓存代理服务提前进行加载。
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包