自己动手写一个JDK Stream
支持和JDK Stream一样的功能, 提供与Stream一样的API,后续会进行更多的API扩展。
| 类型 | 方法 | |
|---|---|---|
| 创建操作 | of(T…t) | 例如River.of(1,2,3,4),创建了一个River |
| 中间操作 | map()limit()sort()peek()skip()filter()distinct() | |
| 终结操作 | toArray()reduce()collect()max()anyMatch()findFirst()等 |
同时River还需要具备延迟处理(遇到终结操作才触发)的特性。
顶层接口-River
在river接口中定义好所有需要支持的方法api
public interface River<E> {
//===============================创建操作=====================================
@SafeVarargs
static <T> River<T> of(T... t) {
return RiverGenerator.create(t);
}
static <T> River<T> of(Collection<T> collection) {
return RiverGenerator.create(collection);
}
//===============================中间操作=====================================
/**
* 将流转换为并行流
*
* @return River
*/
River<E> parallel();
/**
* 将流转换为串行流
*
* @return River
*/
River<E> sequential();
/**
* 过滤操作
*
* @param predicate 过滤的表达式
* @return 过滤后的River
*/
River<E> filter(Predicate<E> predicate);
/**
* 元素去重操作
*
* @return 去重后的River
*/
River<E> distinct();
/**
* 限制River的元素数量
*
* @param size 元素的最大数量
* @return River
*/
River<E> limit(int size);
/**
* 排序
*
* @param comparable 比较器
* @return 添加排序后的River
*/
River<E> sort(Comparator<E> comparable);
/**
* 对元素进行预操作
*
* @param consumer 执行的操作
* @return 新River
*/
River<E> peek(Consumer<E> consumer);
/**
* 跳过指定数量的元素
*
* @param size 要跳过的元素数
* @return new River
*/
River<E> skip(int size);
/**
* 元素转换映射
*
* @param function 映射执行逻辑
* @return new River
*/
<E_OUT> River<E_OUT> map(Function<? super E, ? extends E_OUT> function);
//===============================终结操作=====================================
/**
* 遍历River所有元素
*
* @param consumer 表达式
*/
void forEach(Consumer<E> consumer);
/**
* 输出一个数组
*
* @return E类型的数组
*/
Object[] toArray();
/**
* 输出元素到参数数组中
*
* @param e 承载元素的数组
*/
void toArray(E[] e);
/**
* 计算元素的数量
*
* @return River中元素的数量
*/
long count();
/**
* 操作
*
* @param identity 初始值
* @param accumulator 操作函数
* @return reduce result
*/
E reduce(E identity, BinaryOperator<E> accumulator);
/**
* 执行操作
*
* @param collector 执行操作的收集器
* @param <R> 结果类型
* @param <A> 中间累加类型
* @return 执行结果
*/
<R, A> R collect(Collector<? super E, A, R> collector);
/**
* 获取比较后,最小的元素
*
* @param comparator 比较器
* @return 最小的元素
*/
Optional<E> min(Comparator<? super E> comparator);
/**
* 获取比较后,最大的元素
*
* @param comparator 比较器
* @return 最大的元素
*/
Optional<E> max(Comparator<? super E> comparator);
/**
* 判断匹配,任意即可
*
* @param predicate
* @return true:match success
*/
boolean anyMatch(Predicate<? super E> predicate);
/**
* 判断匹配,所有都要匹配
*
* @param predicate
* @return
*/
boolean allMatch(Predicate<? super E> predicate);
/**
* 判断匹配,都不要匹配上
*
* @param predicate
* @return
*/
boolean noneMatch(Predicate<? super E> predicate);
/**
* 获取第一个元素
*
* @return
*/
Optional<E> findFirst();
}
River实现类 – AbstractRiverPipeline
River接口的实现主要都在AbstractRiverPipeline类中, 以filter() 为例,返回了一个新的River对象,典型的流式编程的实现方式。
方法事情主要两个:
-
new一个新的River的实现类。 -
在 accept()方法中实现wrapSink(),这个方法在后续构建SinkChain时候需要调用。
public class AbstractRiverPipeline<I, O>
extends Pipeline<I, O> implements River<O> {
//存储元素的spliterator对象引用
protected Spliterator sourceSpliterator;
...
/**
* 追加filter操作
* 创建一个filter的{@link PipelineStage},然后将该stage追到到Pipeline的尾部
*
* @param predicate 过滤的表达式
* @return 新增的filter对象
*/
@Override
public River<O> filter(Predicate<O> predicate) {
return new PipelineStage<O, O>(this) {
@Override
public SinkChain<O, O> wrapSink(SinkChain<O, ?> sink) {
SinkChain<O, O> sinkChain = new SinkChain<O, O>() {
@Override
public void accept(O t) {
if (!predicate.test(t)) {
return;
}
getNext().accept(t);
}
};
sinkChain.setNext(sink);
return sinkChain;
}
};
}
...
}
返回的对象是PipelineStage,是River的子类,扩展了一些于Sink相关的方法。
阶段封装-PipelineStage
PipelineStage表示一个阶段,什么是阶段?调用filter()后,就相当整个链中添加了一个阶段,可以理解为链表中的节点。
java复制代码public class PipelineStage<I, O> extends AbstractRiverPipeline<I, O> {
public PipelineStage(Spliterator<I> spliterator) {
this.setSourceSpliterator(spliterator);
this.isParallel = false;
}
/**
* @param river 上一个stage
*/
public PipelineStage(AbstractRiverPipeline<?, I> river) {
previous = river;
isParallel = river.isParallel;
sourceSpliterator = river.sourceSpliterator;
}
public Object[] getArray() {
throw new UnsupportedOperationException("to override");
}
public Object getState() {
throw new UnsupportedOperationException("to override");
}
public void setState(O s) {
}
@Override
public PipelineStage<I, O> clone() {
throw new UnsupportedOperationException("to override");
}
}
不过stage中基于前驱指针previous链接的,所以后续wrapSink时候也是,也是从尾到头的方式。
假设我们的代码是这样
java
复制代码River.of(1,2,3).filter().distinct()
of()操作生成第一个stage,filter()操作生成第二个stage,distinct()操作生成第三个stage。整体看下来就是这样:
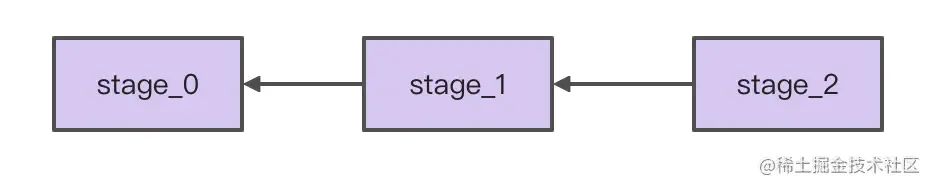
Head阶段生成-RiverGenerator
head是指第一个River对象,也可以表示为stage0。River接口中默认实现了of()方法,调用的就是RiverGenerator.create()
java复制代码public static <E> River<E> create(E... e) {
Spliterator<E> spliterator = Arrays.spliterator(e);
PipelineStage<E, E> head = new PipelineStage<E, E>(spliterator) {
@Override
public SinkChain<E, E> wrapSink(SinkChain<E, ?> sink) {
SinkChain<E, E> sinkChain = new SinkChain<E, E>() {
@Override
public void accept(E t) {
next.accept(t);
}
};
sinkChain.setNext(sink);
return sinkChain;
}
};
head.setSourceSpliterator(spliterator);
return head;
}
流的处理链-SinkChain
任何时候,在调用终结操作之前,一切操作都只是通过stage链连接在一起,并没有进行任何实际的处理操作,这就需要一个开关来启动流,这个开关放在了所有终结操作中,看下AbstractRiverPipeline.forEach() 方法
@Override
public void forEach(Consumer<O> consumer) {
PipelineStage<O, O> stage = new PipelineStage<O, O>(this) {
@Override
public SinkChain<O, O> wrapSink(SinkChain<O, ?> sink) {
return new SinkChain<O, O>() {
@Override
public void accept(O t) {
consumer.accept(t);
}
};
}
};
// 启动流的开关
evaluate(stage);
}
evaluate() 主要做两件事:
-
将所有stage包装成 SinkChain。(对相关名词概念不清楚的可以看之前的Stream源码解析文章) -
启动流,对所有元素进行处理。
private void evaluate(PipelineStage<?, O> stage) {
//构建处理链
SinkChain<O, O> sinkHead = warpPipeline(stage);
//开始处理
sinkHead.begin(-1);
//遍历元素
sinkHead.getSourceSpliterator().forEachRemaining(sinkHead);
sinkHead.end();
}
包装 – wrapPipeline
顺序是从尾到头进行的,返回的sink是第一个阶段。
private SinkChain<O, O> warpPipeline(AbstractRiverPipeline river) {
SinkChain<O, O> sink = null;
for (; river != null; river = river.previous) {
sink = river.wrapSink(sink);
}
return sink;
}
这里的wrapSink() 的逻辑对应的就是AbstractRiverPipeline中重写的逻辑
这样返回的对象就是一条sink链了,并且链中每一个sink都有自己的begin() 、accept() 、end() 方法。
流的运行流程
evaluate第二部分的工作是运行流
-
首先调用 begin()方法,从头到尾执行一遍所有对象的begin()方法,主要作用是进行初始化。 -
forEachRemaining的作用就是对数据源spliterator元素执行accept()方法,可以从头倒尾一个个执行。 -
最后调用 end()方法,从头到尾执行一遍,主要目的是数据的情况,字段设为null等。
依然用上面的filter()方法和distinct()为例:
@Override
public River<O> filter(Predicate<O> predicate) {
return new PipelineStage<O, O>(this) {
@Override
public SinkChain<O, O> wrapSink(SinkChain<O, ?> sink) {
SinkChain<O, O> sinkChain = new SinkChain<O, O>() {
@Override
public void accept(O t) {
// 如果不符合要求,不再向后传递该元素,该元素的处理到此为止
if (!predicate.test(t)) {
return;
}
//如何要求则调用下一个sink的accept()方法
getNext().accept(t);
}
};
sinkChain.setNext(sink);
return sinkChain;
}
};
}
@Override
public River<O> distinct() {
return new PipelineStage<O, O>(this) {
@Override
public SinkChain<O, O> wrapSink(SinkChain<O, ?> sink) {
SinkChain<O, O> sinkChain = new SinkChain<O, O>() {
private HashSet<O> set;
@Override
public void begin(int n) {
//执行初始化工作
this.set = new HashSet<>(n > 0 ? n : 16);
//调用下一个sink的begin()方法
super.begin(n);
}
@Override
public void end() {
this.set = null;
super.end();
}
@Override
public void accept(O t) {
if (!set.add(t)) {
return;
}
getNext().accept(t);
}
};
sinkChain.setNext(sink);
return sinkChain;
}
};
}
总结
文章只是列举了一些关键步骤的设计与实现,设计的思路大多数来源于JDK Stream的源码,如何实现一个Stream,主要的目的是可以更好的理解Stream一些地方为什么要那么设计,因为只有在自己开发的时候才能体会到设计的精妙。
项目的源码在github,测试代码在test包下,目前只支持串行流,后续会添加并行流的支持,并且提供更多的API,让River可以进行更多更强大的操作。
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包