Keepalived使用教程
假设你搭建了一个电商网站
一开始你只有一台 web 服务器对用户提供服务,用户可以直接连接你的web服务器去实现各项需求

随着你的业务不断扩大,你发现单机模式下你的电商网站支撑不了那么大的流量,随时会出现宕机的风险
于是你使用了分布式架构,并使用nginx实现负载均衡功能
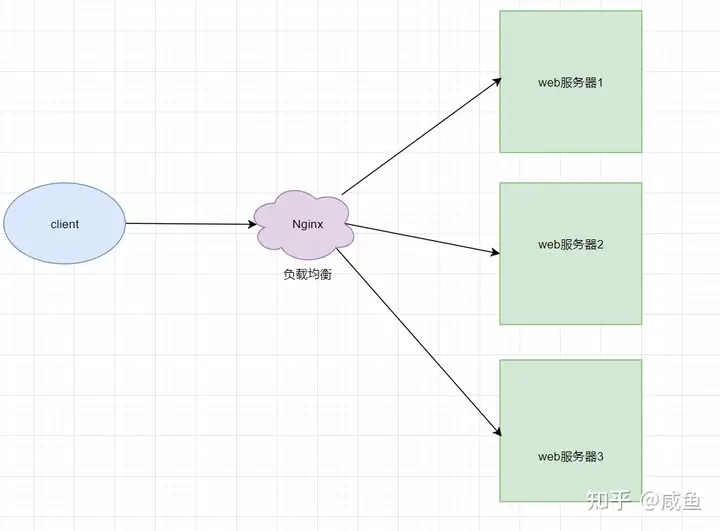
有了分布式架构+负载均衡,你的业务可用性越来越强,能承受住很高的流量
但是问题出现了——所有流量都打在 nginx代理上,你的nginx容易出现性能瓶颈
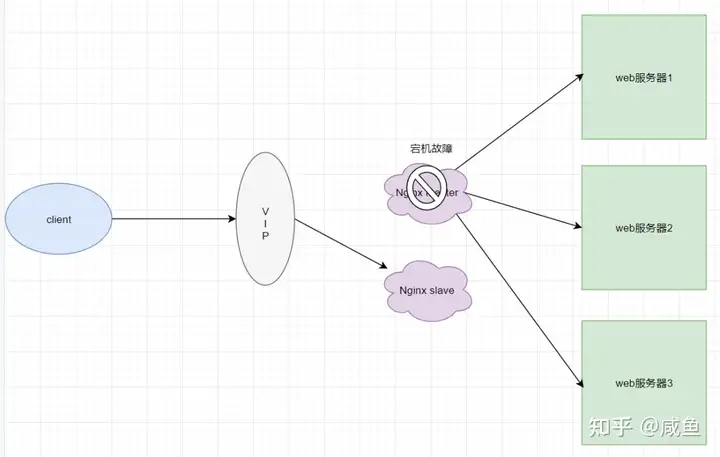
突然有一天,你的 nginx 撑不了那么大的流量,出现了宕机故障,那么用户发起的所有请求都到不了你的后端 web 服务器上
那么该如何解决 nginx 单点问题呢?
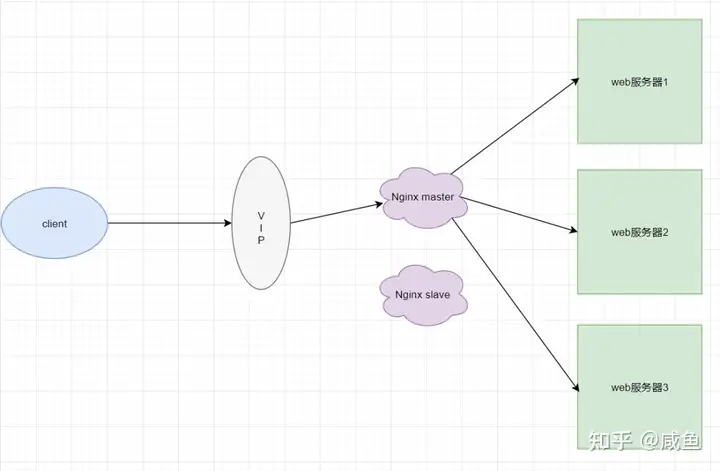
你想到了将 nginx 做成分布式+ keepalived 的方式
如果 nginx master 出现宕机,keepalived则会将服务切到 nginx slave上,保证业务不受影响
这样就可以避免 nginx 单机故障问题,以此来实现高可用
Keepalived,中文意思即保活。可以理解为保证业务/服务/服务器存活
初识Keepalived
Keepalived是Linux下一个轻量级别的高可用解决方案,通过虚拟路由冗余协议来实现服务或者网络的高可用
起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态
如果某个服务器节点出现故障,Keepalived将检测到后自动将节点从集群系统中剔除
而在故障节点恢复正常后,Keepalived又可以自动将此节点重新加入集群中
这些工作自动完成,不需要人工干预,需要人工完成的只是修复出现故障的节点
特点:
1、部署简单,只需要配置一个配置文件即可
2、加入了虚拟路由冗余协议,可以保证业务或网络不间断稳定运行
核心功能:
1、健康检查
采用tcp三次握手,icmp请求,http请求,udp 、
echo请求等方式对负载均衡器后面的实际的服务器(通常是承载真实业务的服务器)进行保活2、故障切换
主要应用在配置了主备的服务器上,使用虚拟路由冗余协议维持主备之间的心跳
当主服务器出现问题时,由备服务器承载对应的业务,从而在最大限度上减少损失,并提供服务的稳定性VRRP协议
在现实的网络环境中,主机之间的通信都是通过配置静态路由(默认网关)来完成的
而主机之间的路由器一旦出现故障,就会通信失败
因此在这种通信模式下,路由器就会有单点瓶颈问题,为了解决这个问题,引入了VRRP 协议(虚拟路由冗余协议)
通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信
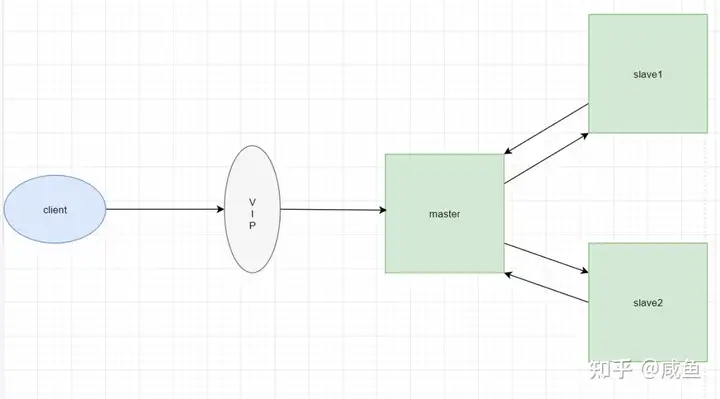
VRRP可以将两台或多台物理路由器设备虚拟成一个虚拟路由器,这个虚拟路由器通过虚拟IP(一个或多个)对外提供服务,而在虚拟路由器内部是多个物理路由器协同工作,VRRP角色如下:
1、角色
- 虚拟路由器:VRRP组中所有的路由器,拥有虚拟的IP+MAC(00-00-5e-00-01-VRID)地址
- 主路由器(master):虚拟路由器内部通常只有一台物理路由器对外提供服务,主路由器是由选举算法产生,对外提供各种网络功能
- 备份路由器(backup):VRRP组中除主路由器之外的所有路由器,不对外提供任何服务,只接受主路由的通告,当主路由器挂掉之后,重新进行选举算法接替master路由器
master路由器由选举算法产生,它拥有对外服务的VIP,提供各种网络服务,如ARP请求、数据转发、ICMP等等,而backup路由器不拥有VIP,也不对外提供网络服务
当master发生故障时,backup将重新进行选举,产生一个新的master继续对外提供服务
2、VRRP工作模式
VRRP有三种工作状态,分别是:
- Initialize状态
- Master状态
- Backup状态
选举机制:
- 优先级
- 抢占模式下,一旦有优先级高的路由器加入,立即成为Master
- 非抢占模式下,只要Master不挂掉,优先级高的路由器只能等待
Keepalived原理
keepalived工作在TCP/IP参考模型的第三、四和第五层,也就是网络层、传输层个和应用层
- 网络层:通过ICMP协议向集群每个节点发送一个ICMP数据包(类似于ping功能),如果某个节点没有返回响应数据包,那么认定此节点发生了故障,Keepalived将报告此节点失效,并从集群中剔除故障节点
- 传输层:通过TCP协议的端口连接和扫描技术来判断集群节点是否正常,keepalived一旦在传输层探测到这些端口没有响应数据返回,就认为这些端口所对应的节点发生故障,从集群中剔除故障节点
- 应用层:用户可以通过编写程序脚本来运行keepalived,keepalived根据脚本来检测各种程序或者服务是否正常,如果检测到有故障,则把对应的服务从服务器中删除
组件架构
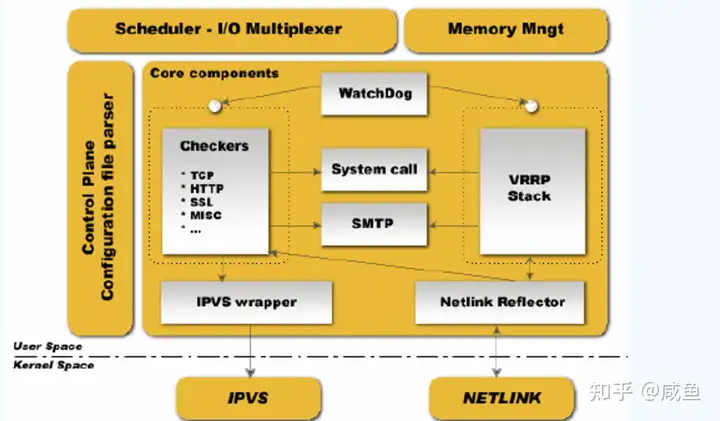
我们将整个体系结构分层用户层和内核层
- Scheduler I/O Multiplexer
I/O复用分发调用器,负责安排Keepalived所有的内部的任务请求
- Memory Management
内存管理机制,提供了访问内存的一下通用方法Keepalived
- Control Plane
控制面板,实现对配置文件的编译和解析,Keepalived的配置文件解析比较特殊,它并不是一次解析所有模块的配置,而是只有在用到某模块时才解析相应的配置
- Core components
Keepalived的核心组件,包含了一系列功能模块,主要有watch dog、Checkers、VRRP Stack、IPVS wrapper、Netlink Reflector
watch dog:
一个极为简单又非常有效的检测工具,针对被监视目标设置一个计数器和阈值,
watch dog会自己增加此计数值,然后等待被监视目标周期性的重置该数值,
一旦被监控目标发生错误,就无法重置该数值,
watch dog就会检测到。Keepalived是通过它来监控Checkers和VRRP进程
Checkers:
实现对服务器运行状态检测和故障隔离
VRRP Stack:
实现HA集群中失败切换功能,通过VRRP功能再结合LVS负载均衡软件即可部署一个高性能的负载均衡集群
IPVS wrapper:
实现IPVS功能,该模块可以将设置好的IPVS规则发送到内核空间并提交给IPVS模块,最终实现负载均衡功能
Netlink Reflector
实现VIP的设置和切换安装&配置
yum install -y keepalived配置文件都是以块(block)的形式组成,每一个块的内容都包含在{ }中
全局配置
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
global_defs
#全局配置标识
notification_email
#用于设置报警的邮件地址,可以设置多个,每行一个。如果要开启邮件报警,需要开启本机的sendmail服务
notification_email_from
#邮件的发送地址
smtp_server
#设置邮件的smtp server地址
smtp_connect_timeout
#设置连接smtp server的超时时间
router_id
# 运行keepalived的一个标识,唯一
vrrp_skip_check_adv_addr
#对所有通告报文都检查,会比较消耗性能,启用此配置后,如果收到的通告报文和上一个报文是同一个路由器,则跳过检查,默认值为全检查
vrrp_strict
#严格遵守VRRP协议,启用此项后以下状况将无法启动服务:1.无VIP地址 2.配置了单播邻居 3.在VRRP版本2中有IPv6地址,开启动此项并且没有配置vrrp_iptables时会自动开启iptables防火墙规则,默认导致VIP无法访问,建议不加此项配置
vrrp_iptables
#此项和vrrp_strict同时开启时,则不会添加防火墙规则,如果无配置vrrp_strict项,则无需启用此项配置
vrrp_garp_interval 0
#gratuitous ARP messages 报文发送延迟,0表示不延迟
vrrp_gna_interval 0
#unsolicited NA messages (不请自来)消息发送延迟VRRP实例配置
vrrp_script nginx_check {
script"/tools/nginx_check.sh"
interval 1
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass test
}
virtual_ipaddress {
192.168.149.100
}
track_script {
nginx_check
}
notify_master /tools/master.sh
notify_backup /tools/backup.sh
notify_fault /tools/fault.sh
notify_stop /tools/stop.sh
}vrrp_instance VI_1 #VRRP实例开始的标识 VI_1为实例名称
state #指定keepalived的角色,MASTER表示此主机是主服务器,BACKUP表示此主机是备服务器
interface #指定检测网络的网卡接口
virtual_router_id #虚拟路由标识,数字形式,同一个VRRP实例使用唯一的标识,即在同一个vrrp_instance下,master和backup必须一致
priority #节点优先级,数字越大表示节点的优先级越高,在一个VRRP实例下,MASTER的优先级必须要比BACKUP高,不然就会切换角色
advert_int #用于设定MASTER与BACKUP之间同步检查的时间间隔,单位为秒
auth_type PASS #预共享密钥认证,同一个虚拟路由器的keepalived节点必须一样
auth_pass #设置密钥
virtual_ipaddress #设置虚拟IP地址,可以设置多种形式:10.0.0.100不指定网卡,默认为eth0,注意:不指定/prefix,默认为/32;10.0.0.101/24 dev eth1 指定VIP的网卡;10.0.0.102/24 dev eth2 label eth2:1 #指定VIP的网卡label
nopreempt # 设置为非抢占模式,同一实例下主备设置必须一样
preemtp_delay # 设置抢占模式的延时时间,单位为秒脚本相关配置
vrrp_script
#自定义资源监控脚本,vrrp实例根据脚本返回值进行下一步操作,脚本可被多个实例调用。
#track_script:调用vrrp_script定义的脚本去监控资源,定义在实例之内,调用事先定义的vrrp_script。实现主备切换,保证服务高可用
#vrrp_script仅仅通过监控脚本返回的状态码来识别集群服务是否正常,如果返回状态码是0,那么就认为服务正常,反之亦然。
notify_master #当前节点成为主节点时触发的脚本
notify_backup #当前节点转为备节点时触发的脚本
notify_fault #当前节点转为“失败”状态时触发的脚本
notify_stop #当停止VRRP时触发的脚本
Nginx+Keepalived案例
本次实验,我们就使用 Nginx + Keepalived实现一个 web 服务高可用方案
本次实验架构图如下:
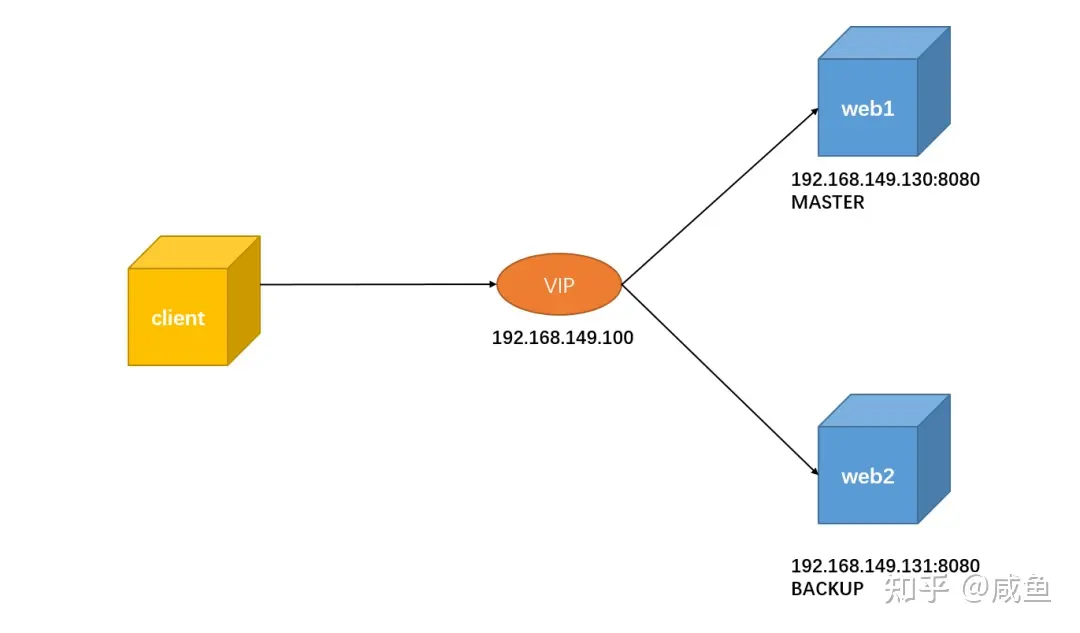
首先安装Nginx
#安装nginx以及拓展源
yum install epel-release -y
yum install -y nginx安装Keepalived
yum install -y keepalived安装完 Nginx 之后接着配置 web 站点
#web1
[root@nginx1 ~]# vim /etc/nginx/conf.d/web.conf
server{
listen 8080;
root /usr/share/nginx/html;
index test.html;
}
[root@nginx1 ~]# echo "<h1>This is web1</h1>" > /usr/share/nginx/html/test.html#web2
[root@nginx2 ~]# vim /etc/nginx/conf.d/web.conf
server{
listen 8080;
root /usr/share/nginx/html;
index test.html;
}
[root@nginx2 ~]# echo "<h1>This is web2</h1>" > /usr/share/nginx/html/test.html接着启动 Nginx
nginx -t
nginx配置Keepalived(不同角色有些选项不一样)
web1:master
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script nginx_check {
script "/tools/nginx_check.sh"
interval 1
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass test
}
virtual_ipaddress {
192.168.149.100
}
track_script {
nginx_check
}
notify_master /tools/master.sh
notify_backup /tools/backup.sh
notify_fault /tools/fault.sh
notify_stop /tools/stop.sh
}web2:slave
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script nginx_check {
script "/tools/nginx_check.sh"
interval 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 52
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass test
}
virtual_ipaddress {
192.168.149.100
}
track_script {
nginx_check
}
notify_master /tools/master.sh
notify_backup /tools/backup.sh
notify_fault /tools/fault.sh
notify_stop /tools/stop.sh
}
还需要编写相关脚本
我们将所有脚本放在同一个目录下,方便我们集中管理
mkdir /tools首先是编写 Keepalived 日志脚本(将每次工作过程输出到日志上)
cd /tools
cat master.sh
ip=$(hostname -I | awk '{print $1}')
dt=$(date+'%Y%m%d %H:%M:%S')
echo"$0--${ip}--${dt}">> /tmp/kp.log
cat backup.sh
ip=$(hostname -I | awk '{print $1}')
dt=$(date+'%Y%m%d %H:%M:%S')
echo"$0--${ip}--${dt}">> /tmp/kp.log
cat fault.sh
ip=$(ip addr|grep inet| grep 192.168 |awk '{print $2}')
dt=$(date +'%Y%m%d %H:%M:%S')
echo"$0--${ip}--${dt}">> /tmp/kp.log
cat stop.sh
ip=$(ip addr|grep inet| grep 192.168| awk '{print $2}')
dt=$(date +'%Y%m%d %H:%M:%S')
echo"$0--${ip}--${dt}">> /tmp/kp.log接着编写健康检查脚本
该脚本对 Nginx 进程进行检测,如果发现 Nginx 进程没了则返回失败(1)
cat nginx_check.sh
#!/bin/bash
result=`pidof nginx`
if [ ! -z "${result}" ];
then
exit 0
else
exit 1
fi
编写完脚本后我们对这些脚本加 x 权限,并启动 Keepalived
cd /tools/ && chmod +x *.sh
systemctl restart keepalived.service验证
现在web1(192.168.149.130)是master
访问192.168.149.100:8080

可以看到访问成功了
然后我们关闭 web1 服务
[root@nginx1 ~]# nginx -s stop可以看到web2(192.168.149.131)获得了VIP,升级成了主
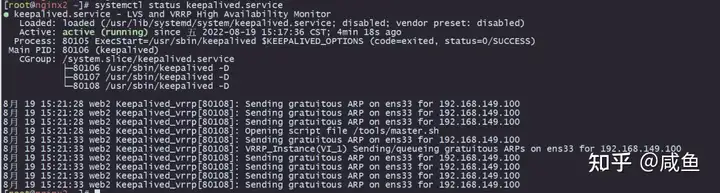
访问192.168.149.100:8080
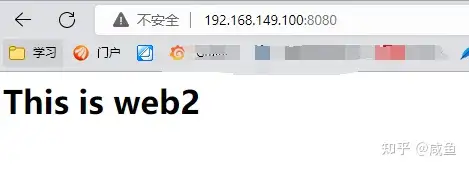
可以发现访问到了 web2 服务器上
之后我们重启 web1 看一下
可以看到web1又变成了master,因为没有配置抢占模式/非抢占模式,所以选举机制是优先级,web1的优先级比web2要高,所以web1启动后就会把master角色拿过来
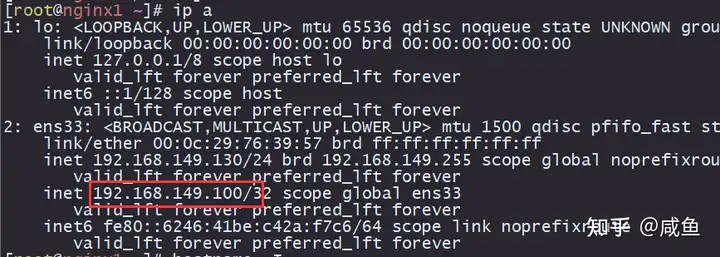
我们再次访问一下看看
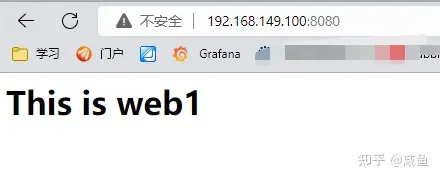
可以看到 web1 服务又可以正常访问了
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包