在真实的业务场景中,我们的业务的数据——例如订单、会员、支付等——都是持久化到数据库中的,因为数据库能有很好的事务保证、持久化保证。但是,正因为数据库要能够满足这么多优秀的功能特性,使得数据库在设计上通常难以兼顾到性能,因此往往不能满足大型流量下的性能要求,像是 MySQL 数据库只能承担“千”这个级别的 QPS,否则很可能会不稳定,进而导致整个系统的故障。
但是客观上,我们的业务规模很可能要求着更高的 QPS,有些业务的规模本身就非常大,也有些业务会遇到一些流量高峰,比如电商会遇到大促的情况。
而这时候大部分的流量实际上都是读请求,而且大部分数据也是没有那么多变化的,如热门商品信息、微博的内容等常见数据就是如此。此时,缓存就是我们应对此类场景的利器。
01
所谓缓存,实际上就是用空间换时间,准确地说是用更高速的空间来换时间,从而整体上提升读的性能。
何为更高速的空间呢?
更快的存储介质。通常情况下,如果说数据库的速度慢,就得用更快的存储组件去替代它,目前最常见的就是 Redis(内存存储)。Redis 单实例的读 QPS 可以高达 10w/s,90% 的场景下只需要正确使用 Redis 就能应对。
就近使用本地内存。就像 CPU 也有高速缓存一样,缓存也可以分为一级缓存、二级缓存。即便 Redis 本身性能已经足够高了,但访问一次 Redis 毕竟也需要一次网络 IO,而使用本地内存无疑有更快的速度。不过单机的内存是十分有限的,所以这种一级缓存只能存储非常少量的数据,通常是最热点的那些 key 对应的数据。这就相当于额外消耗宝贵的服务内存去换取高速的读取性能。
02
用空间换时间,意味着数据同时存在于多个空间。最常见的场景就是数据同时存在于 Redis 与 MySQL 上(为了问题的普适性,后面举例中若没有特别说明,缓存均指 Redis 缓存)。
实际上,最权威最全的数据还是在 MySQL 里的。而万一 Redis 数据没有得到及时的更新(例如数据库更新了没更新到 Redis),就出现了数据不一致。
大部分情况下,只要使用了缓存,就必然会有不一致的情况出现,只是说这个不一致的时间窗口是否能做到足够的小。有些不合理的设计可能会导致数据持续不一致,这是我们需要改善设计去避免的。
这里的一致性实际上对于本地缓存也是同理的,例如数据库更新后没有及时更新本地缓存,也是有一致性问题的,下文统一以 Redis 缓存作为引子讲述,实际上处理本地缓存原理基本一致。
缓存不一致性无法客观地完全消灭
为什么我们几乎没办法做到缓存和数据库之间的强一致呢?
理想情况下,我们需要在数据库更新完后把对应的最新数据同步到缓存中,以便在读请求的时候能读到新的数据而不是旧的数据(脏数据)。但是很可惜,由于数据库和 Redis 之间是没有事务保证的,所以我们无法确保写入数据库成功后,写入 Redis 也是一定成功的;即便 Redis 写入能成功,在数据库写入成功后到 Redis 写入成功前的这段时间里,Redis 数据也肯定是和 MySQL 不一致的。如下两图所示:
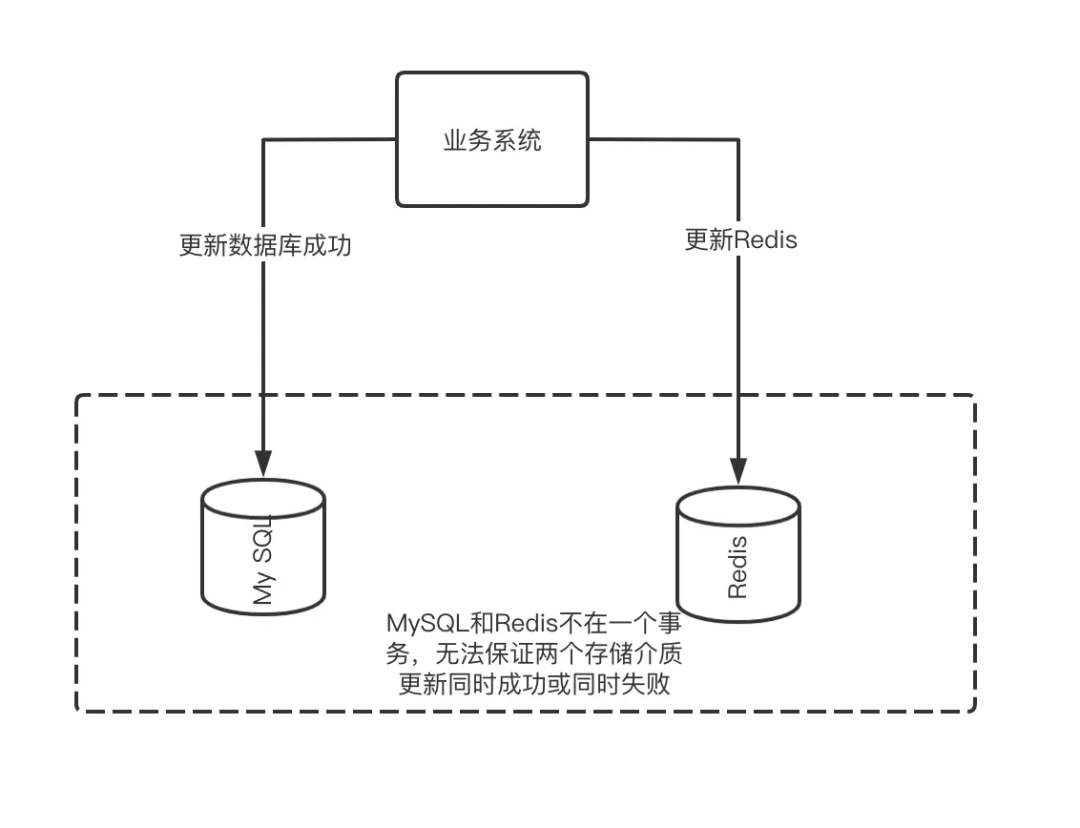
无法事务保持一致
所以说这个时间窗口是没办法完全消灭的,除非我们付出极大的代价,使用分布式事务等各种手段去维持强一致,但是这样会使得系统的整体性能大幅度下降,甚至比不用缓存还慢,这样不就与我们使用缓存的目标背道而驰了吗?
不过虽然无法做到强一致,但是我们能做到的是缓存与数据库达到最终一致,而且不一致的时间窗口我们能做到尽可能短,按照经验来说,如果能将时间优化到 1ms 之内,这个一致性问题带来的影响我们就可以忽略不计。
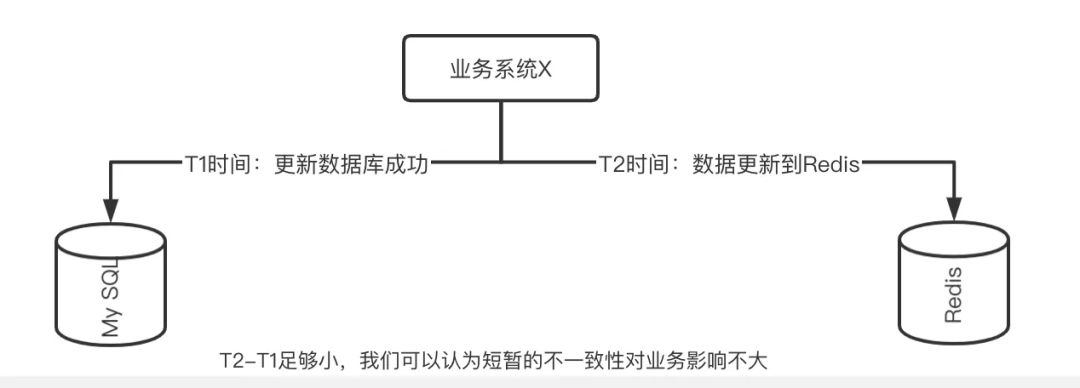
03
data = queryDataRedis(key);if (data ==null) {data = queryDataMySQL(key); //缓存查询不到,从MySQL做查询if (data!=null) {updateRedis(key, data);//查询完数据后更新MySQL最新数据到Redis}}
也就是说优先查询缓存,查询不到才查询数据库。如果这时候数据库查到数据了,就将缓存的数据进行更新。这是我们常说的 cache aside 的策略,也是最常用的策略。
这样的逻辑是正确的,而一致性的问题一般不来源于此,而是出现在处理写请求的时候。所以我们简化成最简单的写请求的逻辑,此时你可能会面临多个选择,究竟是直接更新缓存,还是失效缓存?而无论是更新缓存还是失效缓存,都可以选择在更新数据库之前,还是之后操作。
这样就演变出 4 个策略:更新数据库后更新缓存、更新数据库前更新缓存、更新数据库后删除缓存、更新数据库前删除缓存。下面我们来分别讲述。
更新数据库后更新缓存的不一致问题
一种常见的操作是,设置一个过期时间,让写请求以数据库为准,过期后,读请求同步数据库中的最新数据给缓存。那么在加入了过期时间后,是否就不会有问题了呢?并不是这样。
大家设想一下这样的场景。
假如这里有一个计数器,把数据库自减 1,原始数据库数据是 100,同时有两个写请求申请计数减一,假设线程 A 先减数据库成功,线程 B 后减数据库成功。那么这时候数据库的值是 98,缓存里正确的值应该也要是 98。
但是特殊场景下,你可能会遇到这样的情况:
- 线程 A 和线程 B 同时更新这个数据。
- 更新数据库的顺序是先 A 后 B。
- 更新缓存时顺序是先 B 后 A。
如果我们的代码逻辑还是更新数据库后立刻更新缓存的数据,那么——
updateMySQL();updateRedis(key, data);
| 时间 | 线程A(写请求) | 线程B(写请求) | 问题 |
| T1 | 更新数据库为99 | ||
| T2 | 更新数据库为98 | ||
| T3 | 更新缓存数据为98 | ||
| T4 | 更新缓存数据为99 | 此时缓存的值被显式更新为99,但是实际上数据库的值已经是98,数据不一致 |
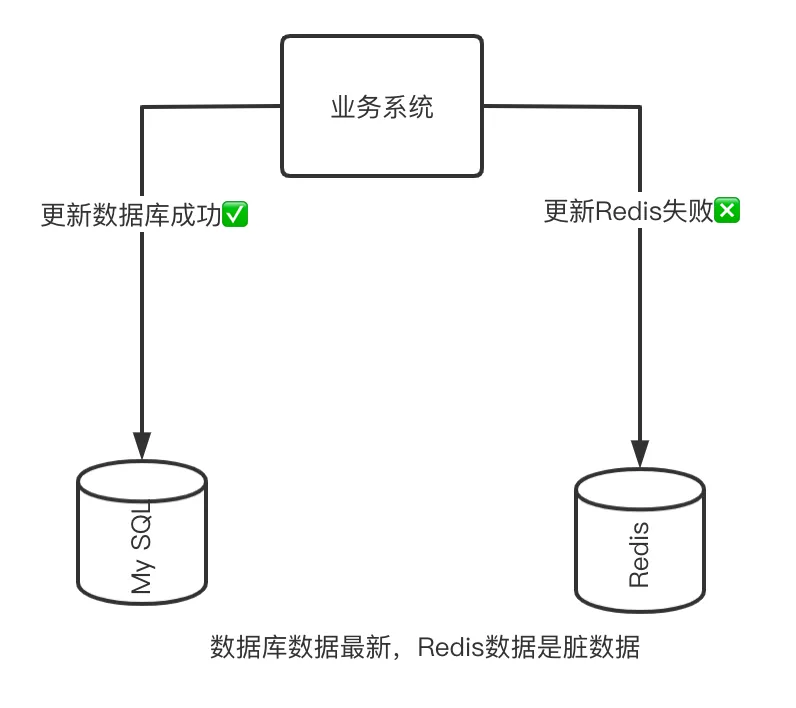
更新数据库前更新缓存的不一致问题
那你可能会想,这是否表示,我应该先让缓存更新,之后再去更新数据库呢?类似这样:
updateRedis(key, data);//先更新缓存updateMySQL();//再更新数据库
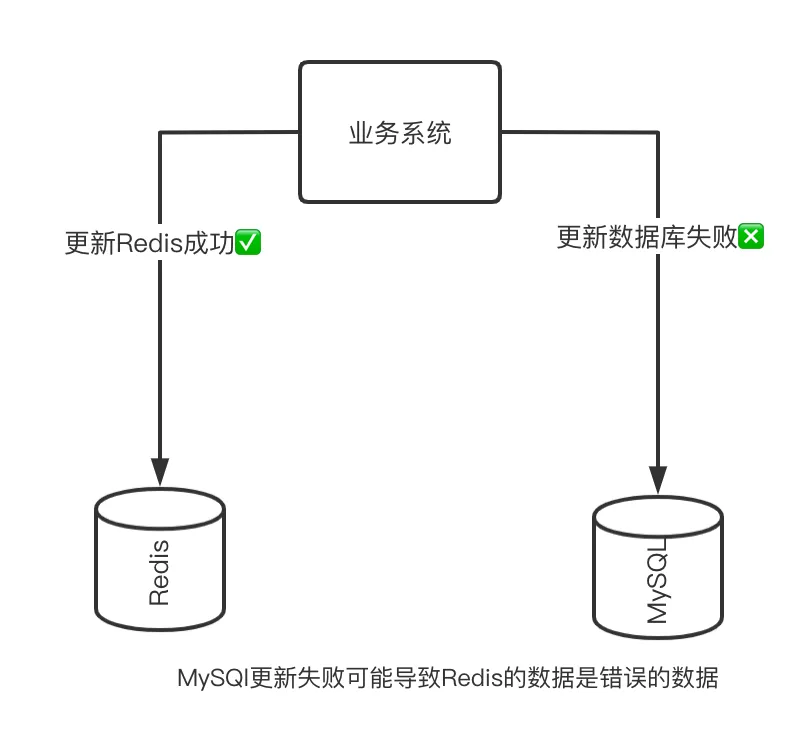
你可能会想,是否我在更新数据库失败的时候做 Redis 回滚的操作能够解决呢?这其实也是不靠谱的,因为我们也不能保证这个回滚的操作 100% 被成功执行。
同时,在写写并发的场景下,同样有类似的一致性问题,请看以下情况:
- 线程 A 和线程 B 同时更新同这个数据。
- 更新缓存的顺序是先 A 后 B。
- 更新数据库的顺序是先 B 后 A。
举个例子。线程 A 希望把计数器置为 0,线程 B 希望置为 1。而按照以上场景,缓存确实被设置为 1,但数据库却被设置为 0。
所以通常情况下,更新缓存再更新数据库是我们应该避免使用的一种手段。
更新数据库前删除缓存的问题
那如果采取删除缓存的策略呢?也就是说我们在更新数据库的时候失效对应的缓存,让缓存在下次触发读请求时进行更新,是否会更好呢?同样地,针对在更新数据库前和数据库后这两个删除时机,我们来比较下其差异。
最直观的做法,我们可能会先让缓存失效,然后去更新数据库,代码逻辑如下:
deleteRedis(key);//先删除缓存让缓存失效updateMySQL();//再更新数据库
这样的逻辑看似没有问题,毕竟删除缓存后即便数据库更新失败了,也只是缓存上没有数据而已。然后并发两个写请求过来,无论怎么样的执行顺序,缓存最后的值也都是会被删除的,也就是说在并发写写的请求下这样的处理是没问题的。
然而,这种处理在读写并发的场景下却存在着隐患。
还是刚刚更新计数的例子。例如现在缓存的数据是 100,数据库也是 100,这时候需要对此计数减 1,减成功后,数据库应该是 99。如果这之后触发读请求,缓存如果有效的话,里面应该也要被更新为 99 才是正确的。
那么思考下这样的请求情况:
- 线程 A 更新这个数据的同时,线程 B 读取这个数据。
- 线程 A 成功删除了缓存里的老数据,这时候线程 B 查询数据发现缓存失效。
- 线程 A 更新数据库成功。
| 时间 | 线程A(写请求) | 线程B(读请求) | 问题 |
| T1 | 删除缓存值 | ||
| T2 | 1.读取缓存数据,缓存缺失,从数据库读取数据100 | ||
| T3 | 更新数据库中的数据X的值为99 | ||
| T4 | 将数据100的值写入缓存 | 此时缓存的值被显式更新为100,但是实际上数据库的值已经是99了 |
可以看到,在读写并发的场景下,一样会有不一致的问题。
针对这种场景,有个做法是所谓的“延迟双删策略”,就是说,既然可能因为读请求把一个旧的值又写回去,那么我在写请求处理完之后,等到差不多的时间延迟再重新删除这个缓存值。
| 时间 | 线程A(写请求) | 线程C(新的读请求) | 线程D(新的读请求) | 问题 |
| T5 | sleep(N) | 缓存存在,读取到缓存旧值100 | 其他线程可能在双删成功前读到脏数据 | |
| T6 | 删除缓存值 | |||
| T7 | 缓存缺失,从数据库读取数据的最新值(99) |
这种解决思路的关键在于对 N 的时间的判断,如果 N 时间太短,线程 A 第二次删除缓存的时间依旧早于线程 B 把脏数据写回缓存的时间,那么相当于做了无用功。而 N 如果设置得太长,那么在触发双删之前,新请求看到的都是脏数据。
更新数据库后删除缓存
那如果我们把更新数据库放在删除缓存之前呢,问题是否解决?我们继续从读写并发的场景看下去,有没有类似的问题。
| 时间 | 线程A(写请求) | 线程B(读请求) | 线程C(读请求) | 潜在问题 |
| T1 | 更新主库 X = 99(原值 X = 100) | |||
| T2 | 读取数据,查询到缓存还有数据,返回100 | 线程C实际上读取到了和数据库不一致的数据 | ||
| T3 | 删除缓存 | |||
| T4 | 查询缓存,缓存缺失,查询数据库得到当前值99 | |||
| T5 | 将99写入缓存 |
可以看到,大体上,采取先更新数据库再删除缓存的策略是没有问题的,仅在更新数据库成功到缓存删除之间的时间差内——[T2,T3)的窗口 ,可能会被别的线程读取到老值。
而在开篇的时候我们说过,缓存不一致性的问题无法在客观上完全消灭,因为我们无法保证数据库和缓存的操作是一个事务里的,而我们能做到的只是尽量缩短不一致的时间窗口。
在更新数据库后删除缓存这个场景下,不一致窗口仅仅是 T2 到 T3 的时间,内网状态下通常不过 1ms,在大部分业务场景下我们都可以忽略不计。因为大部分情况下一个用户的请求很难能再 1ms 内快速发起第二次。
但是真实场景下,还是会有一个情况存在不一致的可能性,这个场景是读线程发现缓存不存在,于是读写并发时,读线程回写进去老值。并发情况如下:
| 时间 | 线程A(写请求) | 线程B(读请求–缓存不存在场景) | 潜在问题 |
| T1 | 查询缓存,缓存缺失,查询数据库得到当前值100 | ||
| T2 | 更新主库 X = 99(原值 X = 100) | ||
| T3 | 删除缓存 | ||
| T4 | 将100写入缓存 | 此时缓存的值被显式更新为100,但是实际上数据库的值已经是99了 |
总的来说,这个不一致场景出现条件非常严格,因为并发量很大时,缓存不太可能不存在;如果并发很大,而缓存真的不存在,那么很可能是这时的写场景很多,因为写场景会删除缓存。
所以待会我们会提到,写场景很多时候实际上并不适合采取删除策略。
总结四种更新策略
终上所述,我们对比了四个更新缓存的手段,做一个总结对比,其中应对方案也提供参考,具体不做展开,如下表:
| 策略 | 并发场景 | 潜在问题 | 应对方案 |
| 更新数据库+更新缓存 | 写+读 | 线程A未更新完缓存之前,线程B的读请求会短暂读到旧值 | 可以忽略 |
| 写+写 | 更新数据库的顺序是先A后B,但更新缓存时顺序是先B后A,数据库和缓存数据不一致 | 分布式锁(操作重) | |
| 更新缓存+更新数据库 | 无并发 | 线程A还未更新完缓存但是更新数据库可能失败 | 利用MQ确认数据库更新成功(较复杂) |
| 写+写 | 更新缓存的顺序是先A后B,但更新数据库时顺序是先B后A | 分布式锁(操作很重) | |
| 删除缓存值+更新数据库 | 写+读 | 写请求的线程A删除了缓存在更新数据库之前,这时候读请求线程B到来,因为缓存缺失,则把当前数据读取出来放到缓存,而后线程A更新成功了数据库 | 延迟双删(但是延迟的时间不好估计,且延迟的过程中依旧有不一致的时间窗口) |
| 更新数据库+删除缓存值 | 写+读(缓存命中) | 线程A完成数据库更新成功后,尚未删除缓存,线程B有并发读请求会读到旧的脏数据 | 可以忽略 |
| 写+读(缓存不命中) | 读请求不命中缓存,写请求处理完之后读请求才回写缓存,此时缓存不一致 | 分布式锁(操作重) |
从一致性的角度来看,采取更新数据库后删除缓存值,是更为适合的策略。因为出现不一致的场景的条件更为苛刻,概率相比其他方案更低。
那么是否更新缓存这个策略就一无是处呢?不是的!
删除缓存值意味着对应的 Key 会失效,那么这时候读请求都会打到数据库。如果这个数据的写操作非常频繁,就会导致缓存的作用变得非常小。而如果这时候某些 Key 还是非常大的热 Key,就可能因为扛不住数据量而导致系统不可用。
如下图所示:
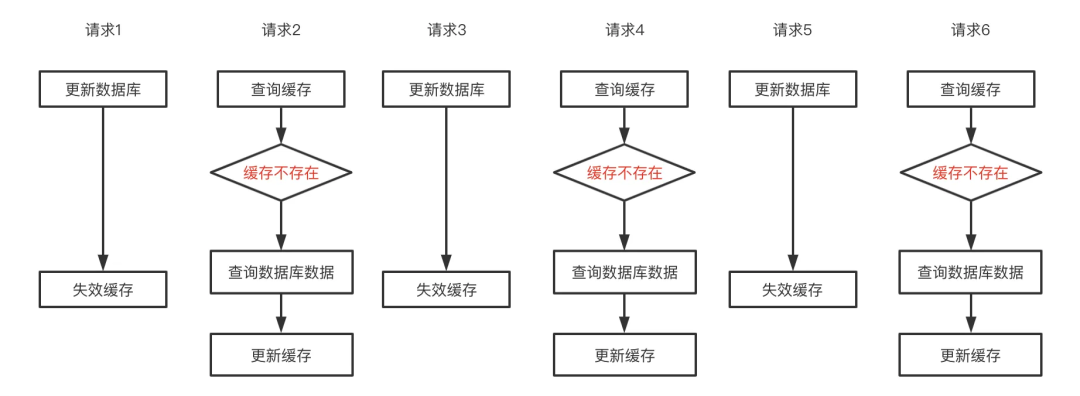
删除策略频繁的缓存失效导致读请求无法利用缓存
所以做个简单总结,足以适应绝大部分的互联网开发场景的决策:
- 针对大部分读多写少场景,建议选择更新数据库后删除缓存的策略。
- 针对读写相当或者写多读少的场景,建议选择更新数据库后更新缓存的策略。
04
缓存设置过期时间
第一个方法便是我们上面提到的,当我们无法确定 MySQL 更新完成后,缓存的更新/删除一定能成功,例如 Redis 挂了导致写入失败了,或者当时网络出现故障,更常见的是服务当时刚好发生重启了,没有执行这一步的代码。
这些时候 MySQL 的数据就无法刷到 Redis 了。为了避免这种不一致性永久存在,使用缓存的时候,我们必须要给缓存设置一个过期时间,例如 1 分钟,这样即使出现了更新 Redis 失败的极端场景,不一致的时间窗口最多也只是 1 分钟。
这是我们最终一致性的兜底方案,万一出现任何情况的不一致问题,最后都能通过缓存失效后重新查询数据库,然后回写到缓存,来做到缓存与数据库的最终一致。
05
万一删除缓存这一步因为服务重启没有执行,或者 Redis 临时不可用导致删除缓存失败了,就会有一个较长的时间(缓存的剩余过期时间)是数据不一致的。
那我们有没有什么手段来减少这种不一致的情况出现呢?这时候借助一个可靠的消息中间件就是一个不错的选择。
因为消息中间件有 ATLEAST-ONCE 的机制,如下图所示。
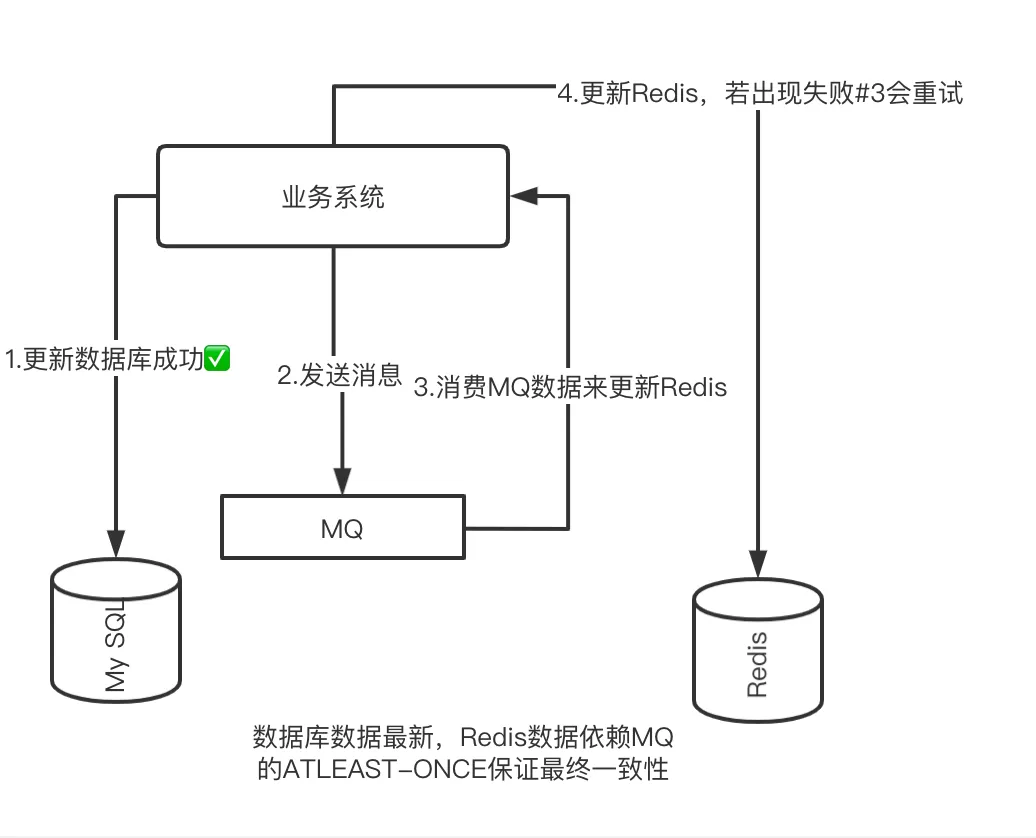
我们把删除 Redis 的请求以消费 MQ 消息的手段去失效对应的 Key 值,如果 Redis 真的存在异常导致无法删除成功,我们依旧可以依靠 MQ 的重试机制来让最终 Redis 对应的 Key 失效。
而你们或许会问,极端场景下,是否存在更新数据库后 MQ 消息没发送成功,或者没机会发送出去机器就重启的情况?
这个场景的确比较麻烦,如果 MQ 使用的是 RocketMQ,我们可以借助 RocketMQ 的事务消息,来让删除缓存的消息最终一定发送出去。而如果你没有使用 RocketMQ,或者你使用的消息中间件并没有事务消息的特性,则可以采取消息表的方式让更新数据库和发送消息一起成功。事实上这个话题比较大了,我们不在这里展开。
06
有些时候,真实的缓存场景并不是数据库中的一个记录对应一个 Key 这么简单,有可能一个数据库记录的更新会牵扯到多个 Key 的更新。还有另外一个场景是,更新不同的数据库的记录时可能需要更新同一个 Key 值,这常见于一些 App 首页数据的缓存。
我们以一个数据库记录对应多个 Key 的场景来举例。
假如系统设计上我们缓存了一个粉丝的主页信息、主播打赏榜 TOP10 的粉丝、单日 TOP 100 的粉丝等多个信息。如果这个粉丝注销了,或者这个粉丝触发了打赏的行为,上面多个 Key 可能都需要更新。只是一个打赏的记录,你可能就要做:
updateMySQL();//更新数据库一条记录deleteRedisKey1();//失效主页信息的缓存updateRedisKey2();//更新打赏榜TOP10deleteRedisKey3();//更新单日打赏榜TOP100
这就涉及多个 Redis 的操作,每一步都可能失败,影响到后面的更新。甚至从系统设计上,更新数据库可能是单独的一个服务,而这几个不同的 Key 的缓存维护却在不同的 3 个微服务中,这就大大增加了系统的复杂度和提高了缓存操作失败的可能性。最可怕的是,操作更新记录的地方很大概率不只在一个业务逻辑中,而是散发在系统各个零散的位置。
针对这个场景,解决方案和上文提到的保证最终一致性的操作一样,就是把更新缓存的操作以 MQ 消息的方式发送出去,由不同的系统或者专门的一个系统进行订阅,而做聚合的操作。如下图:
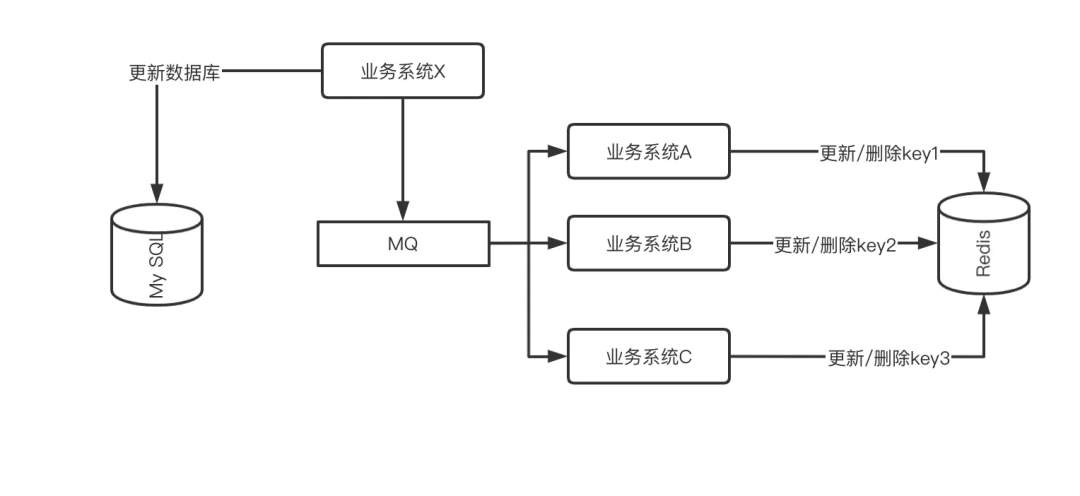
不同业务系统订阅 MQ 消息单独维护各自的缓存 Key
07
上面讲到的 MQ 处理方式需要业务代码里面显式地发送 MQ 消息。还有一种优雅的方式便是订阅 MySQL 的 binlog,监听数据的真实变化情况以处理相关的缓存。
例如刚刚提到的例子中,如果粉丝又触发打赏了,这时候我们利用 binlog 表监听是能及时发现的,发现后就能集中处理了,而且无论是在什么系统什么位置去更新数据,都能做到集中处理。
目前业界类似的产品有 Canal,具体的操作图如下:
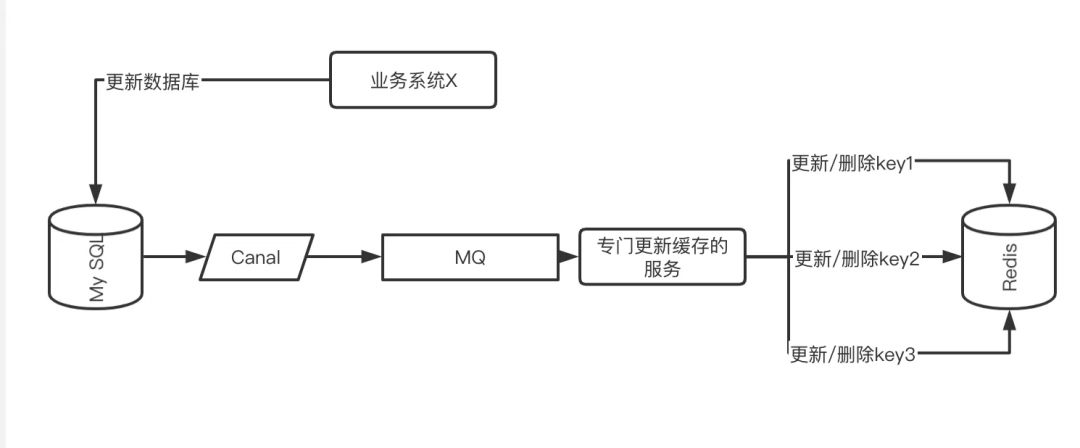
利用 Canel 订阅数据库 binlog 变更从而发出 MQ 消息,让一个专门消费者服务维护所有相关 Key 的缓存操作
到这里,针对大型系统缓存设计如何保证最终一致性,我们已经从策略、场景、操作方案等角度进行了细致的讲述,希望能对你起到帮助。

 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包