写着简单和跑得快是一回事,SQL 为什么不可能跑得快?
然而,如果采用的程序语言不给力,就有可能真地写不出来,这时候就干瞪眼忍受低速度。
SELECT TOP 10 * FROM Orders ORDER BY Amount DESC遗憾的是,用 SQL 无法描述这样的计算过程,只能写成上面那个样子,然后指望数据库去优化。所幸,几乎所有数据库都会优化这个句子,没有傻到去做大排序了,所以也能跑得比较快。
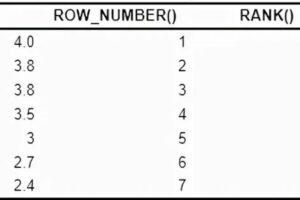
SELECT * FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount DESC) rnFROM Orders )WHERE rn<=10
无论如何,这里还是有 ORDER BY 字样,其中的运算逻辑还是要排序。我们实际测试发现,在 Oracle 中,同样的数据量,计算这种分组前 10 名要比上面那个全集前 10 名慢出几十倍,按说多个分组应该只慢一点点才对。Oracle 有很大可能性真地去做了排序甚至是外存排序(当然我们没读过 Oracle 的源代码并不能确定),数据库优化引擎在这种稍复杂的情况下就晕掉了,只能老老实实按 SQL 写的逻辑去执行,性能就会陡降。
WITH e1 AS (
SELECT userid, visittime AS step1_time, MIN(sessionid) AS sessionid, 1 AS step1
FROM defined_events e1 JOIN eventgroup ON eventgroup.id = e1.eventgroup
WHERE visittime >= DATE_ADD(arg_date,INTERVAL -14 day) AND visittime < arg_date AND eventgroup.name='SiteVisit'
GROUP BY userid,visittime
), e2 AS (
SELECT e2.userid, MIN(e2.sessionid) AS sessionid, 1 AS step2, MIN(visittime) AS step2_time, MIN(e1.step1_time) AS step1_time
FROM defined_events e2 JOIN e1 ON e1.sessionid = e2.sessionid AND visittime > step1_time JOIN eventgroup ON eventgroup.id = e2.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND eventgroup.name = 'ProductDetailPage'
GROUP BY e2.userid
), e3 AS (
SELECT e3.userid, MIN(e3.sessionid) AS sessionid, 1 AS step3, MIN(visittime) AS step3_time, MIN(e2.step1_time) AS step1_time
FROM defined_events e3 JOIN e2 ON e2.sessionid = e3.sessionid AND visittime > step2_time
JOIN eventgroup ON eventgroup.id = e3.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND (eventgroup.name = 'OrderConfirmationType1')
GROUP BY e3.userid
)
SELECT s.devicetype AS devicetype,
COUNT(DISTINCT CASE WHEN funnel_conversions.step1 IS NOT NULL THEN funnel_conversions.step1_userid ELSE NULL END) AS step1_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step2 IS NOT NULL THEN funnel_conversions.step2_userid ELSE NULL END) AS step2_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step3 IS NOT NULL THEN funnel_conversions.step3_userid ELSE NULL END) AS step3_count,
COUNT(DISTINCT CASE WHEN funnel_conversions.step3 IS NOT NULL THEN funnel_conversions.step3_userid ELSE NULL END)
/ COUNT(DISTINCT CASE WHEN funnel_conversions.step1 IS NOT NULL THEN funnel_conversions.step1_userid ELSE NULL END) AS step3_rate
FROM (
SELECT e1.step1_time AS step1_time, e1.userid AS userid, e1.userid AS step1_userid, e2.userid AS step2_userid,e3.userid AS step3_userid,
e1.sessionid AS step1_sessionid, step1, step2, tep3
FROM e1 LEFT JOIN e2 ON e1.userid=e2.userid LEFT JOIN e3 ON e2.userid=e3.userid ) funnel_conversions
LEFT JOIN sessions s ON funnel_conversions.step1_sessionid = s.id
GROUP BY s.devicetype
那就不用 SQL,用 C++,Java 这些去写好了。
所以,代码能写着简单就变得非常有意义了。一方面是短小,这意味着工作量少,另一方面还要容易,这意味着更多的程序员可以写。从这个角度上看,写着简单和跑得快是一回事。想跑得快,就是要有一种程序语言能让高性能算法写着简单,这才有可操作性。
Orders.groups(;top(10;-Amount)Orders.groups(Area;top(10;-Amount))
漏斗分析用 SPL 写出来是这样:
| A | |
| 1 | =now() |
| 2 | =eventgroup=file(“eventgroup.btx”).import@b() |
| 3 | =devicetype=file(“devicetype.btx”).import@b() |
| 4 | =long(elapse(arg_date,-14)) |
| 5 | =long(arg_date) |
| 6 | =long(arg_date+1) |
| 7 | =A2.(case(NAME,”SiteVisit”:1,”ProductDetailPage”:2,”OrderConfirmationType1″:3;null)) |
| 8 | =file(“defined_events.ctx”).open() |
| 9 | =A8.cursor@m(USERID,SESSIONID,VISITTIME,EVENTGROUPNO;VISITTIME>=A4 && VISITTIME<A6,EVENTGROUPNO:A7:#) |
| 10 | =sessions=file(“sessions.ctx”).open().cursor@m(USERID,ID,DEVICETYPENO;;A9) |
| 11 | =A9.joinx@m(USERID:SESSIONID,A10:USERID:ID,DEVICETYPENO) |
| 12 | =A11.group(USERID) |
| 13 | =A12.new(~.align@a(3,EVENTGROUPNO):e,e(1).select(VISITTIME<A5).group@u1(VISITTIME):e1,e(2).group@o(SESSIONID):e2,e(3):e3) |
| 14 | =A13.run(e=join@m(e1:e1,SESSIONID;e2:e2,SESSIONID).select(e2=e2.select(VISITTIME>e1.VISITTIME && VISITTIME<e1.VISITTIME+86400000).min(VISITTIME) ) ) |
| 15 | =A14.run(e0=e1.id(DEVICETYPENO),e1=e.min(e1.VISITTIME),e2=e.min(e2),e=e.min(e1.SESSIONID),e3=e3.select(SESSIONID==e && VISITTIME>e2 && VISITTIME<e1+86400000).min(VISITTIME),e=e0) |
| 16 | =A15.news(e;~:DEVICETYPE,e2,e3) |
| 17 | =A16.groups(DEVICETYPE;count(1):STEP1_COUNT,count(e2):STEP2_COUNT,count(e3):STEP3_COUNT,null:STEP3_RATE) |
| 18 | =A17.run(DEVICETYPE=devicetype.m(DEVICETYPE).DEVICETYPE,STEP3_RATE=STEP3_COUNT/STEP1_COUNT) |
| 19 | =interval@s(A1,now()) |
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。侵权投诉:375170667@qq.com