前言
之前就有考虑过想要研究下RediSearch,号称高性能全文索引的功能,这几天闲来无事调研了一番。
RediSearch 介绍
RediSearch 是 Redis Labs 提供的一款强大且高效的搜索和全文索引引擎。它是一个基于 Redis 的模块,允许用户在 Redis 数据库中进行复杂的搜索和全文检索操作,而无需将数据导出到其他搜索引擎。
推荐使用场景
RediSearch适合简单且高效的分词搜索场景。
针对较为复杂的全文搜索RediSearch肯定是不如ES这种专业的。但假设有一批地址信息,以医院地址举例,省市县地址这些基本字段,想要快速搜索对应地址一般如下解决方案。
- 使用Like进行模糊匹配:太过鸡肋,(比如数据是 【上海市徐汇区宜山路第六人民医院】,搜索关键词是【上海第六】肯定是搜索不到数据的)。
- ES全文索引: 大材小用,杀鸡焉用牛刀
- 自实现分词和倒排索引,最不推荐!吃力不讨好,尽管市面上有很多中文分词器和全文索引的插件。
这时候就很适合使用RediSearch,既可以实现简单的(倒排索引)。又不需要使用ES那么庞大的中间件,集成起来也相对简单。
RediSearch安装
RediSearch 官方推荐的 Docker 方式来安装并启动。
| docker run –name redisearch -p 16379:6379 -v redis-data:/data redis/redis-stack-server:latest |
--name redisearch对容器进行命名-p 16379:6379宿主机16379映射了容器6379端口-v redis-data:/data数据卷映射redis/redis-stack-server:latest表示采用redis-stack-server的最新版本
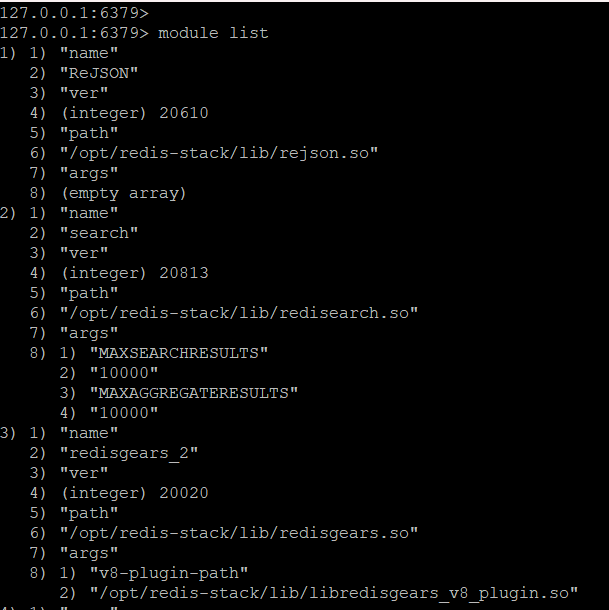
然后进入容器中查看是否存在对应模块
| docker exec -it redisearch redis-cli |
如下图
RediSearch 创建索引和文档
创建索引
| FT.CREATE hospitalIndex ON HASH PREFIX 1 hospital: LANGUAGE “chinese” SCHEMA id NUMERIC province TEXT SORTABLE city TEXT SORTABLE name TEXT SORTABLE |
FT.CREATE hospitalIndex 1.0表示创建一个名为hospitalIndex的全文索引ON HASH表示数据结构为HashPREFIX 1 hospital:表示是Key是以hospital:为前缀的数据LANGUAGE "chinese指定数据的语言为中文。这对文本分析和分词很重要,因为针对不同语言有对应的分词器。SCHEMA id NUMERIC province TEXT SORTABLE city TEXT SORTABLE name TEXT SORTABLE表示字段结构是 id,provice city name 其中id为数字类型,其他字段为文本参与索引
添加索引文档
| ft.add hospitalIndex hospital:1 1.0 language “chinese” fields id 1 province “上海市” city “上海市” name “上海市第六人民医院” | |
| ft.add hospitalIndex hospital:2 1.0 language “chinese” fields id 2 province “上海市” city “上海市” name “上海交通大学医学院附属瑞金医院” | |
| ft.add hospitalIndex hospital:3 1.0 language “chinese” fields id 3 province “上海市” city “上海市” name “上海交通大学医学院附属新华医院” | |
| ft.add hospitalIndex hospital:4 1.0 language “chinese” fields id 4 province “上海市” city “上海市” name “上海交通大学医学院附属上海儿童医学中心” | |
| ft.add hospitalIndex hospital:5 1.0 language “chinese” fields id 5 province “上海市” city “上海市” name “复旦大学附属中山医院” |
FT.ADD hospitalIndex hospital:1 1.0:将一个文档 hospital:1 添加到 hospitalIndex 索引中,评分为 1.0。LANGUAGE "chinese":指定文档的语言为中文。一定要指定对应的语言,这里会采用中文默认的分词器。FIELDS:后面跟着一系列字段和对应的值。
查询
ft.search [index] [keywords] language [lang]
从索引名Index中查找对应keywords,而lang为对应语言,默认会按照语言对应的分词器进行分词。
示例1
| ft.search hospitalIndex “上海市医院” language “chinese” |
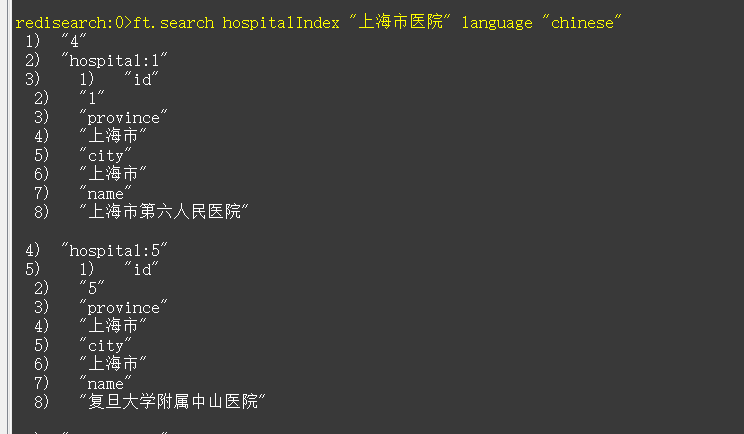
示例2
| ft.search hospitalIndex “上海市交通大学新华医院” language “chinese” |

示例3
| ft.search hospitalIndex “附属医院” language “chinese” |
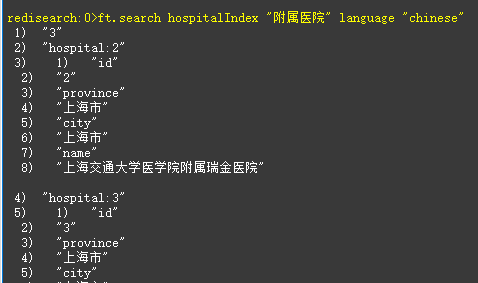
不足之处
示例1
尽快已经基本实现了全文索引,但由于RediSearch中的中文分词器还是有些局限性的。
比如下的几个搜索:

如上图所示,上海市第六 是可以搜索到数据的,但 上海第六 就无法搜索到数据了,这是因为RediSearch中的中文分词器对应拆分不好
示例2
如下图

上面的几个搜索例子其实不够恰当
不过我想强调的主要的目的还是 针对如果分词中的部分词性出现了【专业词】(比如:阿莫西林) 或者类似【第六人】这种现象,RediSearch没办法正确分词的。 是需要专业的分词器和自定义字典的
示例3
还有个问题是RediSearch中分词对应拆词颗粒度过于细,针对短语的搜索是不够的,聚合搜索效果很差,因为我这次的演示数据是地址数据所以不好展示处出来。
具体可以参考地址
RediSearch 中默认的中文分词器可能会根据版本的不一致有差异,一般都是 Friso
当然 RediSearch是支持自定义中文分词器和自定义字典的,不过那就是另外的话题了,这里就不提了。
具体可以参考官网:https://redis.io/docs/latest/commands/ft.dictadd/
删除索引
| ft.drop hospitalIndex |
RediSearch 总结
| 角度 | 优势 | 缺点 |
|---|---|---|
| 场景 | 适合简单的数据类型和文本 | 不适合复杂的数据类型,比如富文本,长文本 |
| 集成难度 | 简单指令, 方便集成 | Redis知识储备,(这个不算什么成本吧) |
| 执行效率 | 基于内存,搜索速度很快 | 分词效果不够理想,数据量大会影响性能 |
| 社区生态 | – | 社区目前过于小众 |
| 部署 | 简单搭建,方便集成,支持集群与横向扩展 | 有一定的不稳定性,毕竟很少见到用于产线环境下。 |
参考地址
- RediSearch/RediSearch
- Redis Real-Time Search, Querying, & Indexing
- RediSearch 高性能的全文搜索引擎
- 关于RediSearch无法正常执行模糊匹配的解决方案
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包