在人工智能(AI)的领域中,当我们提到“XXB”(例如6B、34B)这样的术语时,它通常指的是模型的参数量,其中“B”代表“Billion”,即“十亿”
与 Llama 2 和 Mistral 7B 等热门模型相比,Gemma 在尺寸方面的优越性能设定了新标准。
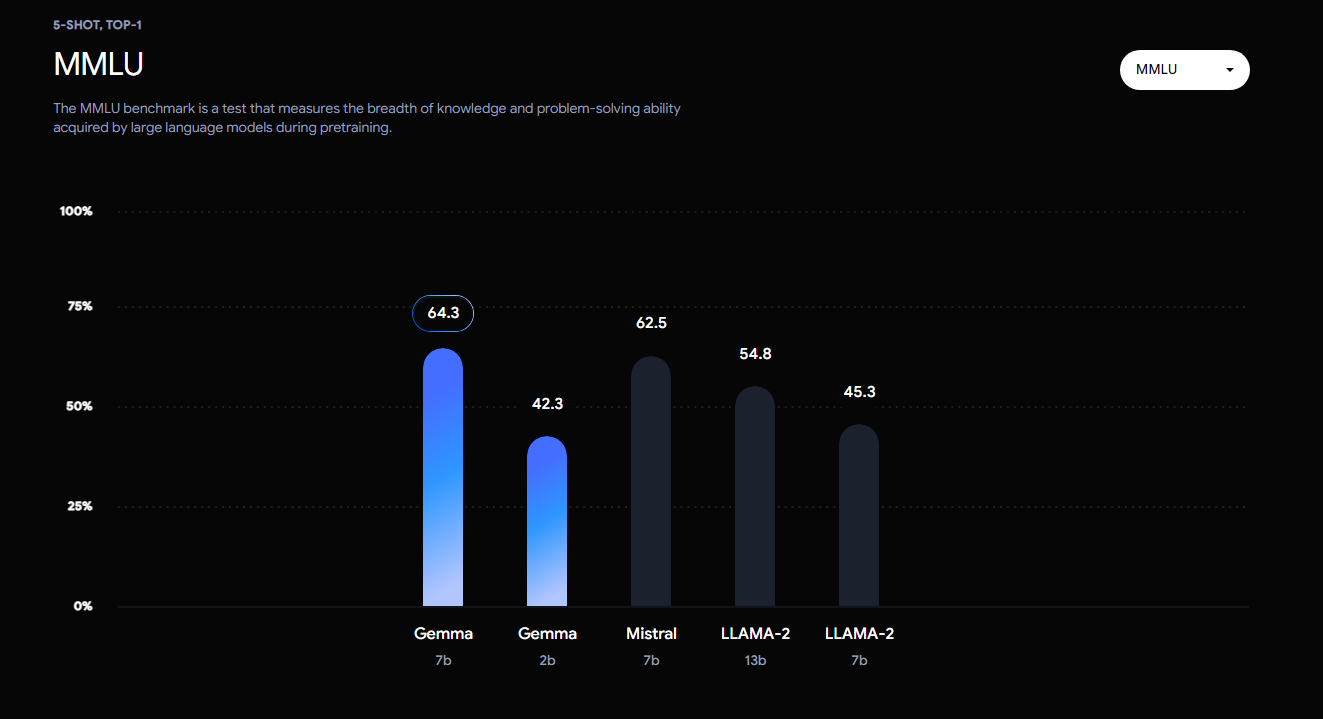
LLaMA 2 (7B) LLaMA 2 (13B) Mistral (7B) Gemma (7B) Qwen(1.5)
Gemma总体表现很强,在众多场景下均有出色发挥。
领先Llama-2是没有疑问的,与Qwen1.5和Mistral则互有胜负。
英文和中文的量词不一样,中文的量词更加细化,个十百千万十万百万千万亿都有。
但是英文没有万这个单独的量词,一万用10个一千来表示,一千万用10个百万来表示,以此类推。
不同的参数量比较难以理解,其实我们可以用人工智能模型中的参数量与生物的神经元数量进行粗略的对比。
就比如拿人类和虫子的神经元数量相比,人类的远远多于虫子,我们的观察结果也比较匹配,那就是人类的智慧在现行的评价体系中远高于虫子。
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。侵权投诉:375170667@qq.com







