要确定哪个MySQL数据库占用CPU高,可以使用以下步骤:
-
使用
SHOW PROCESSLIST查询当前所有活跃的数据库操作。 -
对每个操作的
Time列进行累加,得到每个操作的总耗时。 -
根据累加的耗时从高到低排序,找出占用CPU高的查询。
以下是相应的SQL脚本:
SELECT
user,
db,
command,
time,
state,
info
FROM
(SELECT * FROM information_schema.processlist) AS pl
ORDER BY time DESC;
这个查询会返回所有活跃的数据库操作的详细信息,包括用户、数据库、命令、耗时、状态以及详细的查询信息。你可以根据time列来判断哪个操作占用了更多的CPU资源。
请注意,这个查询可能会对数据库性能产生影响,特别是在数据库负载非常高时。在生产环境中,应该谨慎使用,并尽量在低峰时段进行这样的分析。
MySQL占用CPU过高 查找原因及解决 多种方式
一、排查有没有地方占用SQL资源过多
1、排查方法 :
> mysql -uroot -p #登陆数据库
>******** #输入数据库密码
2、查看数据库
show databases;
3、use 数据库名; #切换到常用数据库
4、show processlist; #显示哪些线程正在运行
或者:
— select * from information_schema.PROCESSLIST where info is not null;
说明各列的含义和用途
id列:一个标识,你要kill 一个语句的时候很有用。
user列: 显示当前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。
host列:显示这个语句是从哪个ip 的哪个端口上发出的。可用来追踪出问题语句的用户。
db列:显示这个进程目前连接的是哪个数据库。
command列:显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)。
通常代表资源未释放,如果是通过连接池,sleep状态应该恒定在一定数量范围内
实战范例:因前端数据输出时(特别是输出到用户终端)未及时关闭数据库连接,导致因网络连接速度产生大量sleep连接,在网速出现异常时,数据库too many connections挂死。
简单解读,数据查询和执行通常只需要不到0.01秒,而网络输出通常需要1秒左右甚至更长,原本数据连接在0.01秒即可释放,但是因为前端程序未执行close操作,直接输出结果,那么在结果未展现在用户桌面前,该数据库连接一直维持在sleep状态!
time列:此这个状态持续的时间,单位是秒。
state列:显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语句执行中的某一个状态,一个sql语句,已查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成。
info列:显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是一个判断问题语句的重要依据。
其中state的状态十分关键,下表列出state主要状态和描述:
| 状态 | 描述 |
| Checking table | 正在检查数据表(这是自动的)。 |
| Closing tables | 正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。 |
| Connect Out | 复制从服务器正在连接主服务器。 |
| Copying to tmp table on disk | 由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。 |
| Creating tmp table | 正在创建临时表以存放部分查询结果。 |
| deleting from main table | 服务器正在执行多表删除中的第一部分,刚删除第一个表。 |
| deleting from reference tables | 服务器正在执行多表删除中的第二部分,正在删除其他表的记录。 |
| Flushing tables | 正在执行FLUSH TABLES,等待其他线程关闭数据表。 |
| Killed | 发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。 |
| Locked | 被其他查询锁住了。 |
| Sending data | 正在处理SELECT查询的记录,同时正在把结果发送给客户端。 |
| Sorting for group | 正在为GROUP BY做排序。 |
| Sorting for order | 正在为ORDER BY做排序。 |
| Opening tables | 这个过程应该会很快,除非受到其他因素的干扰。例如,在执ALTER TABLE或LOCK TABLE语句行完以前,数据表无法被其他线程打开。正尝试打开一个表。 |
| Removing duplicates | 正在执行一个SELECT DISTINCT方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。 |
| Reopen table | 获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。 |
| Repair by sorting | 修复指令正在排序以创建索引。 |
| Repair with keycache | 修复指令正在利用索引缓存一个一个地创建新索引。它会比Repair by sorting慢些。 |
| Searching rows for update | 正在讲符合条件的记录找出来以备更新。它必须在UPDATE要修改相关的记录之前就完成了。 |
| Sleeping | 正在等待客户端发送新请求. |
| System lock | 正在等待取得一个外部的系统锁。如果当前没有运行多个mysqld服务器同时请求同一个表,那么可以通过增加–skip-external-locking参数来禁止外部系统锁。 |
| Upgrading lock | INSERT DELAYED正在尝试取得一个锁表以插入新记录。 |
| Updating | 正在搜索匹配的记录,并且修改它们。 |
| User Lock | 正在等待GET_LOCK()。 |
| Waiting for tables | 该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE,或OPTIMIZE TABLE。 |
| waiting for handler insert | INSERT DELAYED已经处理完了所有待处理的插入操作,正在等待新的请求。 |
二、开启日志排查模式
1、设置
日志开启 — SET GLOBAL log_output = ‘TABLE’;SET GLOBAL general_log = ‘ON’;
日志关闭 — SET GLOBAL log_output = ‘TABLE’; SET GLOBAL general_log = ‘OFF’;
2、开启后 会查询到当前正在运行的sql,如发现SQL周期性一直在执行一段SQL或多段SQL 查找使用地方排查原因
SELECT * from mysql.general_log ORDER BY event_time DESC;
3、在查询到所需要的记录之后,应尽快关闭日志模式,占用磁盘空间比较大,清空表(delete对于这个表,不允许使用,只能用truncate)
— truncate table mysql.general_log;
三、mysql中的wait_timeout坑
mysql> show variables like ‘%timeout%’;
首先解释一下:
wait_timeout — 指的是mysql在关闭一个非交互的连接之前所要等待的秒数,其取值范围为1-2147483(Windows),1-31536000(linux),默认值28800。
interactive_time — 指的是mysql在关闭一个交互的连接之前所要等待的秒数(交互连接如mysql gui tool中的连接),其取值范围随wait_timeout变动,默认值28800。
所谓的交互式连接,即在mysql_real_connect()函数中使用了CLIENT_INTERACTIVE选项。说得直白一点,通过mysql客户端连接数据库是交互式连接,通过jdbc连接数据库是非交互式连接。
MySQL 的默认设置下,当一个连接的空闲时间超过8小时后,一到高峰期肯定会造成,会有太多的TCP连接没关闭,数据库连接数肯定是不够。从而会产生CPU占用过高,服务器告警等问题。因EPG的一个访问一次对数据库操作量不大,查询完数据就完成ok了,wait_timeout 设置在120s内就行了
1、第一种修改方式 需重启MySQL(6.5为例)
1.1、修改参数配置文件
vi /etc/my.cnf
[mysqld]
wait_timeout = 28800
interactive_timeout = 28800
#增加以上两列即可,因为官方文档要求修改此参数必须同时修改interactive_timeout
1.2、重启数据库
service mysqld restart
1.3、查看数据库参数是否修改成功
连接MySQL 然后查看 show variables like ‘wait_timeout’;
2、第二种修改方式 不需重启MySQL
mysql> show variables like ‘%timeout’;
+————————-+——-+
| Variable_name | Value |
+————————-+——-+
| connect_timeout | 10 |
| delayed_insert_timeout | 300 |
| interactive_timeout | 200 |
| net_read_timeout | 30 |
| net_write_timeout | 60 |
| slave_net_timeout | 3600 |
| table_lock_wait_timeout | 50 |
| wait_timeout | 200 |
+————————-+——-+
mysql> set global interactive_timeout=100;
Query OK, 0 rows affected (0.00 sec)
退出后重新登录mysql
如果修改interactive_timeout的话wait_timeout也会跟着变,而只修改wait_timeout是不生效的。
一. 问题锁定

通过top命令查看服务器CPU资源使用情况,明确CPU占用率较高的是否是mysqld进程,如果是则可以明确CUP飘高的原因就是MySQL数据库导致的。
二. QPS激增会导致CPU飘高
分析:

(引用网图)
在有监控工具的情况下,通过查看CPU利用率曲线图和QPS曲线图进行对比,如果CPU曲线图和QPS曲线图波动情况基本保持一致,出现CPU过高则必然和QPS激增有关系,至此可以明确CUP过高是QPS上升导致。反之,如果CUP曲线图对比QPS曲线图有不同步的峰值抖动,则说明在QPS未明显激增的情况下,CPU出现飘高,则大概率跟慢SQL有关,可以进行后续的慢SQL排查分析。
解决(依据情况选用以下办法):
● 如果是实际业务激增导致则可以通过资源扩充,满足业务激增的业务需求。
● 找到具体激增的查询所对应应用系统的接口,进行限流控制,以保护数据库并发访问量。
● 应用采用读写分离,降低单点访问压力。
● 查看SQL是否存在循环插入或更新的情况,改动批量操作。
备注:
● 如果没有监控工具协助QPS分析的情况下,可以通过show global status like ‘Questions’ 和show global status like ‘Uptime’查询,将两者相除得到就是QPS值。
三. 慢SQL会导致CPU飘高
分析(通过show processlist)

通过show processlist查看当前MySQL线程运行情况,主要通过 Time 连接时间和State当前SQL所处的状态来分析慢SQL,一般情况下如果存在Sending data说明该查询较慢,可以将info中的SQL复制出来通过explain查看详细的执行计划进行分析。
分析(通过MySQL自带的慢SQL日志功能)
通过root登录数据库开启慢SQL查询日志,set global slow_query_log = ‘ON’,并设置慢SQL过滤时间set global long_query_time = 1(超过1秒视为慢SQL),指定慢SQL日志文件存放路径set global slow_query_log_file = ‘/var/lib/mysql/test_1116.log’。通过持续观察该慢SQL记录日志文件,查找出具体的慢SQL复制出来通过explain查看详细的执行计划进行分析。
解决(依据情况选用以下办法)
● 紧急处理先通过 kill process id,先kill对应线程,缓解问题。
● 无索引或者索引失效,新建有效索引或者优化SQL语句。
● SQL中有大量聚合操作:简化SQL,将逻辑提炼到业务代码中;聚合操作异步化或预处理。
● SQL返回的数据过多:分页查询。
● 读写较多锁竞争激烈:分库分表或读写分离。
四. 大量空闲连接会导致CPU飘高
分析:
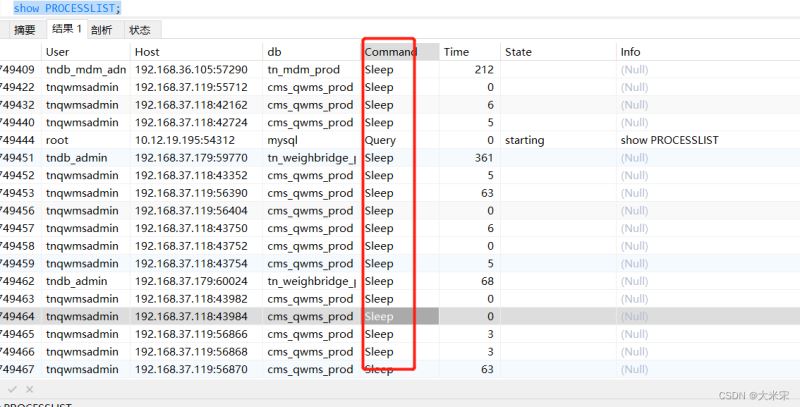
通过 show full processlist 查看Comand 有大量的Sleep,再根据Time查看装填时间是否很长,如果存在大量长时间睡眠线程占用数据库连接,会导致数据库的吞吐量下降,进而导致阻塞也会引发CPU飘高的现象。
解决:
● 修改mysql配置文件中的 wait_timeout 空闲等待时间,值越小则相对空闲线程就会越少,重启mysql生效。
● 也可以通过 set global wat_timeout=xx 方式热修改该参数。
五. MySQL问题排查常用命令
5.1 SQL 执行计划,进行SQL执行分析。
explain + sql 。

5.2 查看数据库当前执行线程状态
show full processlist : 其中重点字段包括Comand 、Time 、State、Info,可以查看当前所有连接线程中命令、持续时间、状态、对应的SQL信息。
5.3 查看当前运行的所有事务

select * from information_schema.INNODB_TRX : 在执行结果中可以看到是否有表锁等待或者死锁,如果有死锁发生,可以通过下面的命令来杀掉当前运行的事务:KILL trx_mysql_thread_id 。
5.4 查看当前出现的锁
select * from information_schema.INNODB_LOCKS:在改结果中可以看到锁的类型、所属事务ID、锁级别、锁模式等信息。
5.5 查看死锁
|
1
2
3
4
5
6
7
8
9
|
SELECT b.trx_state, e.state, e.time, d.state AS block_state, d.time AS block_time, a.requesting_trx_id, a.requested_lock_id, b.trx_query, b.trx_mysql_thread_id, a.blocking_trx_id, a.blocking_lock_id, c.trx_query AS block_trx_query, c.trx_mysql_thread_id AS block_trx_mysql_tread_idFROM information_schema.INNODB_LOCK_WAITS aLEFT JOIN information_schema.INNODB_TRX b ON a.requesting_trx_id = b.trx_idLEFT JOIN information_schema.INNODB_TRX c ON a.blocking_trx_id = c.trx_idLEFT JOIN information_schema.PROCESSLIST d ON c.trx_mysql_thread_id = d.idLEFT JOIN information_schema.PROCESSLIST e ON b.trx_mysql_thread_id = e.idORDER BY a.requesting_trx_id; |
5.5 查看InnoDB状态
|
1
|
SHOW ENGINE INNODB STATUS |
以上就是MySQL CPU过高的排查方法的详细内容,更多关于MySQL CPU过高排查的资料请关注脚本之家其它相关文章!
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包