关于 SQL 语句加了哪些锁的案例分析
首先众所周知,InnoDB 三种行锁:
-
Record Lock(记录锁) :锁住某一行记录 -
Gap Lock(间隙锁) :锁住一段左开右开的区间 -
Next-key Lock(临键锁) :锁住一段左开右闭的区间
哪些语句上面会加行锁?
1)对于常见的 DML 语句(如 UPDATE、DELETE 和 INSERT ),InnoDB 会自动给相应的记录行加写锁
2)默认情况下对于普通 SELECT 语句,InnoDB 不会加任何锁,但是在 Serializable 隔离级别下会加行级读锁
上面两种是隐式锁定,InnoDB 也支持通过特定的语句进行显式锁定:
3)SELECT * FROM table_name WHERE ... FOR UPDATE,加行级写锁
4)SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE,加行级读锁
前置知识就不过多介绍了,在学习具体行锁加锁规则之前,小伙伴们需要记住加锁规则的两条核心:
1)查找过程中访问到的对象才会加锁
这句话该怎么理解?比如有主键 id 为
1 2 3 4 5 ... 10的 10 条记录,我们要找到id = 7的记录。注意,查找并不是从第一行开始一行一行地进行遍历,而是根据 B+ 树的特性进行二分查找,所以一般存储引擎只会访问到要找的记录行(id = 7)的相邻区间
2)加锁的基本单位是 Next-key Lock
下面结合实例帮助大伙分析一条 SQL 语句上面究竟被 InnoDB 自动加上了多少个锁
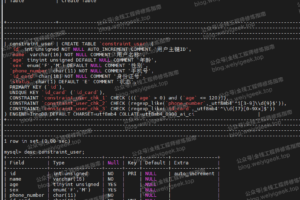
假设有这么一张 user 表,id 为主键(唯一索引),a 是普通索引(非唯一索引),b都是普通的列,其上没有任何索引:
| id (唯一索引) | a (非唯一索引) | b |
|---|---|---|
| 10 | 4 | Alice |
| 15 | 8 | Bob |
| 20 | 16 | Cilly |
| 25 | 32 | Druid |
| 30 | 64 | Erik |
案例 1:唯一索引等值查询
当我们用唯一索引进行等值查询的时候,根据查询的记录是否存在,加锁的规则会有所不同:
-
当查询的记录是存在的,Next-key Lock 会退化成记录锁 -
当查询的记录是不存在的,Next-key Lock 会退化成间隙锁
查询的记录存在
先来看个查询的记录存在的案例:
select * from user
where id = 25
for update;
结合加锁的两条核心:查找过程中访问到的对象才会加锁 + 加锁的基本单位是 Next-key Lock(左开右闭),我们可以分析出,这条语句的加锁范围是 (20, 25]
不过,由于这个唯一索引等值查询的记录 id = 25 是存在的,因此,Next-key Lock 会退化成记录锁,因此最终的加锁范围是 id = 25 这一行
查询的记录不存在
再来看查询的记录不存在的案例:
select * from user
where id = 22
for update;
结合加锁的两条核心:查找过程中访问到的对象才会加锁 + 加锁的基本单位是 Next-key Lock(左开右闭),我们可以分析出,这条语句的加锁范围是 (20, 25]
这里为什么是
(20,25]而不是(20, 22],因为 id = 22 的记录不存在呀,InnoDB 先找到 id = 20 的记录,发现不匹配,于是继续往下找,发现 id = 25,因此,id = 25 的这一行被扫描到了,所以整体的加锁范围是(20, 25]
由于这个唯一索引等值查询的记录 id = 22 是不存在的,因此,Next-key Lock 会退化成间隙锁,因此最终在主键 id 上的加锁范围是 Gap Lock (20, 25)
案例 2:唯一索引范围查询
唯一索引范围查询的规则和等值查询的规则一样,只有一个区别,就是唯一索引的范围查询需要一直向右遍历到第一个不满足条件的记录,下面结合案例来分析:
select * from user
where id >= 20 and id < 22
for update;
先来看语句查询条件的前半部分 id >= 20,因此,这条语句最开始要找的第一行是 id = 20,结合加锁的两个核心,需要加上 Next-key Lock (15,20]。又由于 id 是唯一索引,且 id = 20 的这行记录是存在的,因此会退化成记录锁,也就是只会对 id = 20 这一行加锁。
再来看语句查询条件的后半部分 id < 22,由于是范围查找,就会继续往后找第一个不满足条件的记录,也就是会找到 id = 25 这一行停下来,然后加 Next-key Lock (20, 25],重点来了,但由于 id = 25 不满足 id < 22,因此会退化成间隙锁,加锁范围变为 (20, 25)。
所以,上述语句在主键 id 上的最终的加锁范围是 Record Lock id = 20 以及 Gap Lock (20, 25)
案例 3:非唯一索引等值查询
当我们用非唯一索引进行等值查询的时候,根据查询的记录是否存在,加锁的规则会有所不同:
1、当查询的记录是存在的,除了会加 Next-key Lock 外,还会额外加间隙锁(规则是向下遍历到第一个不符合条件的值才能停止),也就是会加两把锁
很好记忆,就是要查找记录的左区间加 Next-key Lock,右区间加 Gap lock
2、当查询的记录是不存在的,Next-key Lock 会退化成间隙锁(这个规则和唯一索引的等值查询是一样的)
查询的记录存在
先来看个查询的记录存在的案例:
select * from user
where a = 16
for update;
结合加锁的两条核心,这条语句首先会对普通索引 a 加上 Next-key Lock,范围是 (8,16]
又因为是非唯一索引等值查询,且查询的记录 a= 16 是存在的,所以还会加上间隙锁,规则是向下遍历到第一个不符合条件的值才能停止,因此间隙锁的范围是 (16,32)
所以,上述语句在普通索引 a 上的最终加锁范围是 Next-key Lock (8,16] 以及 Gap Lock (16,32)
查询的记录不存在
再来看查询的记录不存在的案例:
select * from user
where a = 18
for update;
结合加锁的两条核心,这条语句首先会对普通索引 a 加上 Next-key Lock,范围是 (16,32]
但是由于查询的记录 a = 18 是不存在的,因此 Next-key Lock 会退化为间隙锁,即最终在普通索引 a 上的加锁范围是 (16,32)。
案例 4:非唯一索引范围查询
范围查询和等值查询的区别在上面唯一索引章节已经介绍过了,就是范围查询需要一直向右遍历到第一个不满足条件的记录,和唯一索引范围查询不同的是,非唯一索引的范围查询并不会退化成 Record Lock 或者 Gap Lock。
select * from user
where a >= 16 and a < 18
for update;
先来看语句查询条件的前半部分 a >= 16,因此,这条语句最开始要找的第一行是 a = 16,结合加锁的两个核心,需要加上 Next-key Lock (8,16]。虽然非唯一索引 a = 16的这行记录是存在的,但此时并不会像唯一索引那样退化成记录锁。
再来看语句查询条件的后半部分 a < 18,由于是范围查找,就会继续往后找第一个不满足条件的记录,也就是会找到 id = 32 这一行停下来,然后加 Next-key Lock (16, 32]。虽然 id = 32 不满足 id < 18,但此时并不会向唯一索引那样退化成间隙锁。
所以,上述语句在普通索引 a 上的最终的加锁范围是 Next-key Lock (8, 16] 和 (16, 32],也就是 (8, 32]。
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包