MySQL 千万不要用 null 了
1、NULL 为什么这么多人用?
2、是不是以讹传讹?
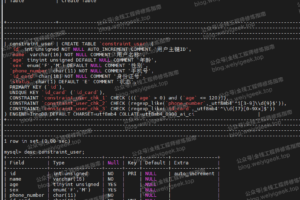
NULL columns require additional space in the rowto record whether their values are NULL. For MyISAM tables, each NULL columntakes one bit extra, rounded up to the nearest byte.
3、给我一个不用 Null 的理由?
注意:但把NULL列改为NOT NULL带来的性能提示很小,除非确定它带来了问题,否则不要把它当成优先的优化措施,最重要的是使用的列的类型的适当性。
create table table_2 (
`id` INT (11) NOT NULL,
user_name varchar(20) NOT NULL
)
create table table_3 (
`id` INT (11) NOT NULL,
user_name varchar(20)
)
insert into table_2 values (4,"zhaoliu_2_1"),(2,"lisi_2_1"),(3,"wangmazi_2_1"),(1,"zhangsan_2"),(2,"lisi_2_2"),(4,"zhaoliu_2_2"),(3,"wangmazi_2_2")
insert into table_3 values (1,"zhaoliu_2_1"),(2, null)
-- 1、NOT IN子查询在有NULL值的情况下返回永远为空结果,查询容易出错
select user_name from table_2 where user_name not in (select user_name from table_3 where id!=1)
mysql root@10.48.186.32:t_test_zz5431> select user_name from table_2 where user_name not
-> in (select user_name from table_3 where id!=1);
+-------------+
| user_name |
|-------------|
+-------------+
0 rows in set
Time: 0.008s
mysql root@10.48.186.32:t_test_zz5431>
-- 2、单列索引不存null值,复合索引不存全为null的值,如果列允许为null,可能会得到“不符合预期”的结果集
-- 如果name允许为null,索引不存储null值,结果集中不会包含这些记录。所以,请使用not null约束以及默认值。
select * from table_3 where name != 'zhaoliu_2_1'
-- 3、如果在两个字段进行拼接:比如题号+分数,首先要各字段进行非null判断,否则只要任意一个字段为空都会造成拼接的结果为null。
select CONCAT("1",null) from dual; -- 执行结果为null。
-- 4、如果有 Null column 存在的情况下,count(Null column)需要格外注意,null 值不会参与统计。
mysql root@10.48.186.32:t_test_zz5431> select * from table_3;
+------+-------------+
| id | user_name |
|------+-------------|
| 1 | zhaoliu_2_1 |
| 2 | <null> |
| 21 | zhaoliu_2_1 |
| 22 | <null> |
+------+-------------+
4 rows in set
Time: 0.007s
mysql root@10.48.186.32:t_test_zz5431> select count(user_name) from table_3;
+--------------------+
| count(user_name) |
|--------------------|
| 2 |
+--------------------+
1 row in set
Time: 0.007s
-- 5、注意 Null 字段的判断方式, = null 将会得到错误的结果。
mysql root@localhost:cygwin> create index IDX_test on table_3 (user_name);
Query OK, 0 rows affected
Time: 0.040s
mysql root@localhost:cygwin> select * from table_3 where user_name is null\G
***************************[ 1. row ]***************************
id | 2
user_name | None
1 row in set
Time: 0.002s
mysql root@localhost:cygwin> select * from table_3 where user_name = null\G
0 rows in set
Time: 0.002s
mysql root@localhost:cygwin> desc select * from table_3 where user_name = 'zhaoliu_2_1'\G
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | table_3
type | ref
possible_keys | IDX_test
key | IDX_test
key_len | 23
ref | const
rows | 1
Extra | Using where
1 row in set
Time: 0.006s
mysql root@localhost:cygwin> desc select * from table_3 where user_name = null\G
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | None
type | None
possible_keys | None
key | None
key_len | None
ref | None
rows | None
Extra | Impossible WHERE noticed after reading const tables
1 row in set
Time: 0.002s
mysql root@localhost:cygwin> desc select * from table_3 where user_name is null\G
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | table_3
type | ref
possible_keys | IDX_test
key | IDX_test
key_len | 23
ref | const
rows | 1
Extra | Using where
1 row in set
Time: 0.002s
mysql root@localhost:cygwin>
-
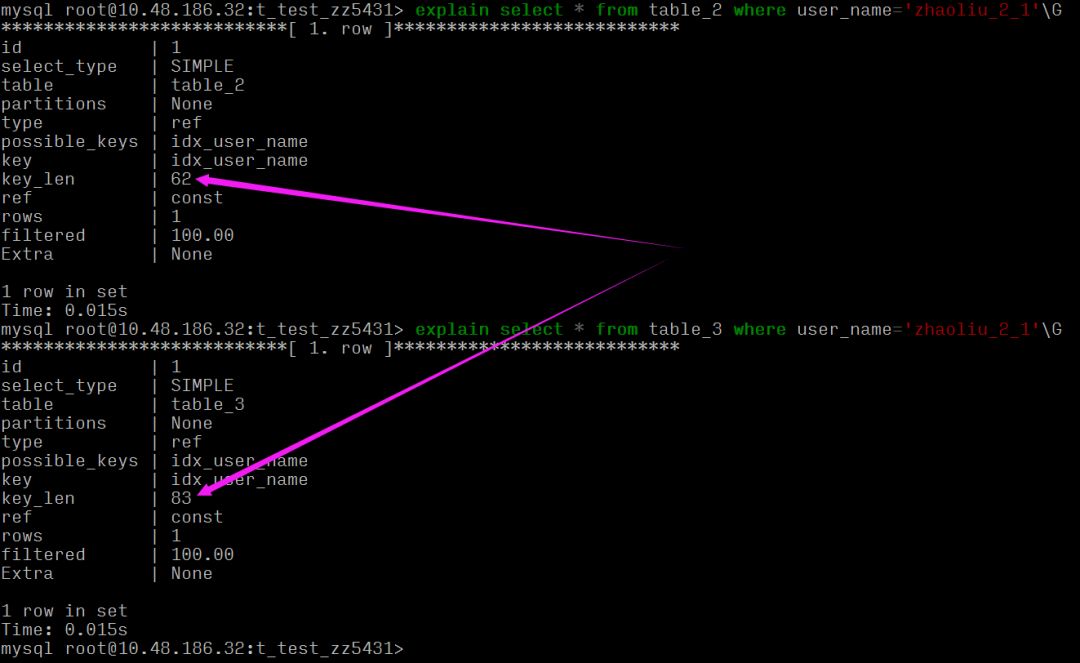
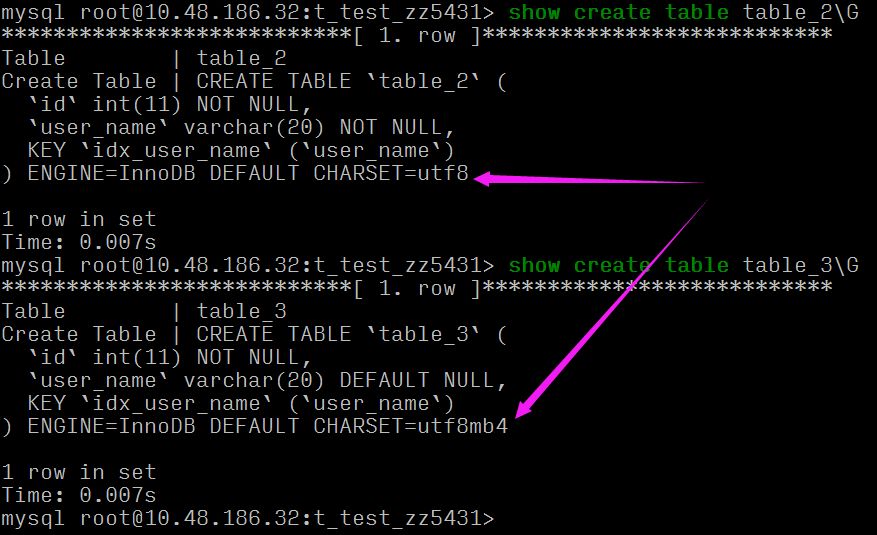
Null 列需要更多的存储空间:需要一个额外字节作为判断是否为 NULL 的标志位
alter table table_3 add index idx_user_name (user_name); alter table table_2 add index idx_user_name (user_name); explain select * from table_2 where user_name='zhaoliu_2_1'; explain select * from table_3 where user_name='zhaoliu_2_1';
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。侵权投诉:375170667@qq.com