音视频转文字不求人,用AI生成中文字幕
本篇文章转载自coder_pig的博客,文章主要分享了如何通过AI生成中文字幕,相信会对大家有所帮助!
coder_pig的博客地址:
https://juejin.cn/post/7291935944117862426
/ 前言 /
如果我没理解错的话,你们的朋友想要的是:
直接生成中文字幕,以便进行电影剧情的解读。
不过,我很抱歉的通知您,不太靠谱🐶, 但也不是不能用,本节我们就来探索用AI下生成中文字幕的过程吧。
/ buzz无脑提取字幕 + Google翻译 /
用 chidiwilliams/buzz 直接选中电影,Language(语言)选中 Japanese(日语),然后点击 Run() 开始生成:
漫长的等待,2小时40分钟的视频,使用tiny模型,足足花了将近25分钟(当然,不排除是我电脑垃圾)打开生成的字幕文件(txt),全选Copy到谷歌翻译看下翻译效果:
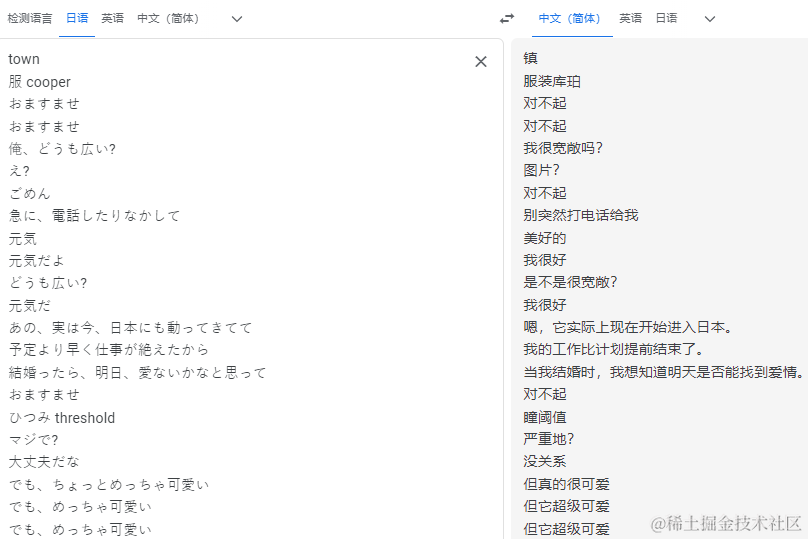
😨 这都什么鬼东西啊???我简单介绍下片头:
河北老乡的前男友打电话给她问好,说自己现在日本,工作提前结束,想约她明天见个面。
感觉有可能是 tiny 模型不行,分别试试 Small、Medium 和 Large,在此之前要截取视频,不然跑一天都可能提取不完,简单点直接裁视频的前10分钟作为样本,这部分对话比较多一些。直接用 ffmpeg 命令截取视频片段:
接着依次选择三个不同的模型进行字幕生成,在漫长等待过程中,我们整下活,看能否提高生成中文字幕的准确率。
/ ffmpeg 提取音频 /
Whisper 在生成字幕时肯定有做 ffmpeg 转换,把视频转换为音频再进行识别,这里我们自己来转一下,可以直接命令行:
也可以 Python 调 ffmepg-python 库来调:
ffmpeg.input(filename=video_path).output(audio_path, af=”pan=1c|c0=c1″, ac=”1″, acodec=’pcm_s16le’, f=’wav’).run()
简单介绍下上面的参数:
- -i:输入的视频文件
- -vn:不处理视频流,只保留音频
- -af “pan=1c|c0=c1” : 音频过滤器,1个声道,第0声道复制第1声道,实现单声道化(就是只取第二个声道,人声一般在右声道)
- -ac 1:输出单声道音频
- -f wav:输出为wav格式
- -acodec pcm_s16le:使用pcm_s16le编码,6位采样深度的无损编码
上面做的事情就是,提取单声道的wav音频,提取的速度非常快啊:
![]()
接着搞下人生分离,就是去掉背景音乐啥的,用Spleeter库来做~
/ Spleeter 提取人声 /
Spleeter 是 Deezer 源分离库,带有用 Python 编写并使用 TensorFlow 的预训练模型。简单点说:可以用它来分离音频文件中的伴奏和人声。使用方法很简单,pip装下库:
接着 Github 仓库下载预测模型:
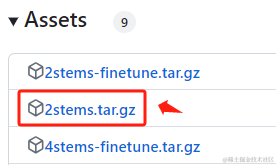
下载后本地创建一个 ****spleeter 文件夹,在里面再创建一个 pretrained_models 文件夹,把下载的压缩包解压到里面,结构如下:
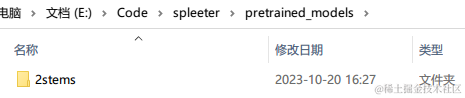
打开命令行,cd 到 spleeter 目录下,键入下述命令:
这里要注意,输入/输出文件的路径不能包含中文!!!不然会报错:Error: Missing argument ‘FILES…‘.

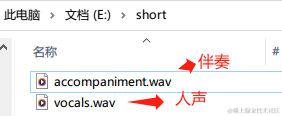
打开生成文件目录,可以看到伴奏和人声,打开听了下人声,伴奏(背景音乐)确实去掉了~
/ Hugging Face 翻译文本 /
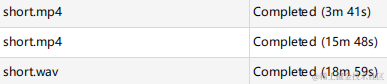
前面切换不同模型进行字幕提取,终于执行完毕了:
依次打开结果验证,直接CV到百度翻译,依旧稀烂:
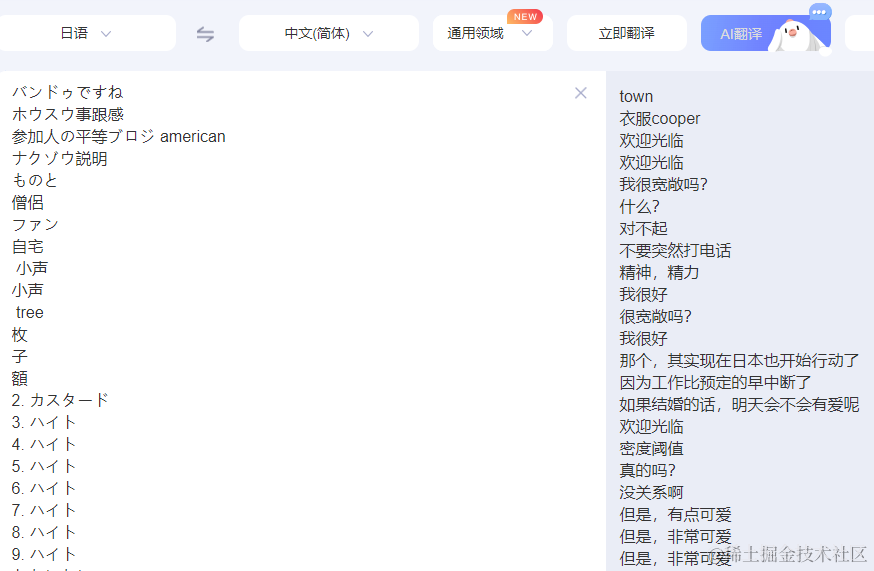
想试试百度这个AI翻译,结果只支持中英互译,搜了下AI离线翻译,结果发现了 Hugging Face,赫尔辛基大学开源免费的多语言翻译模型(目前1440个):
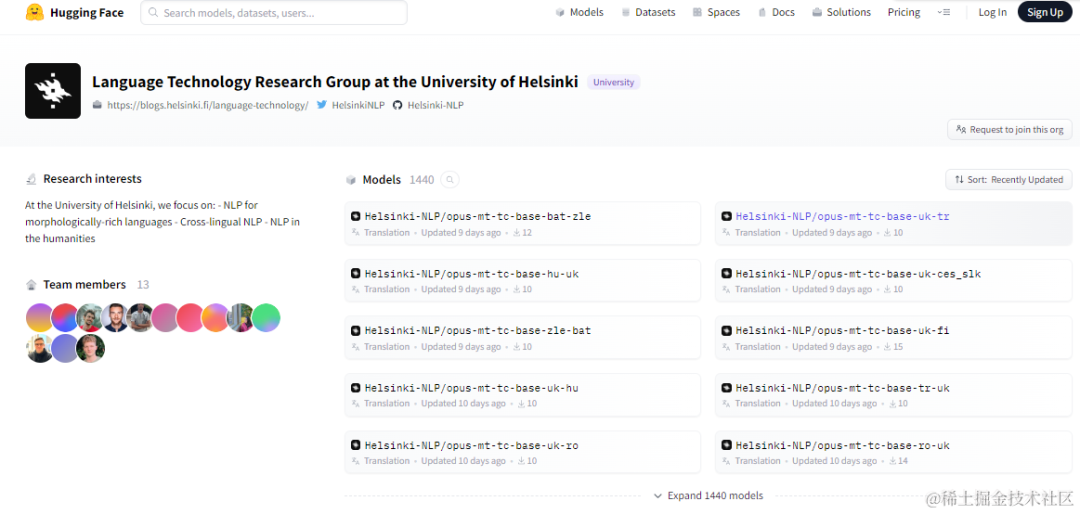
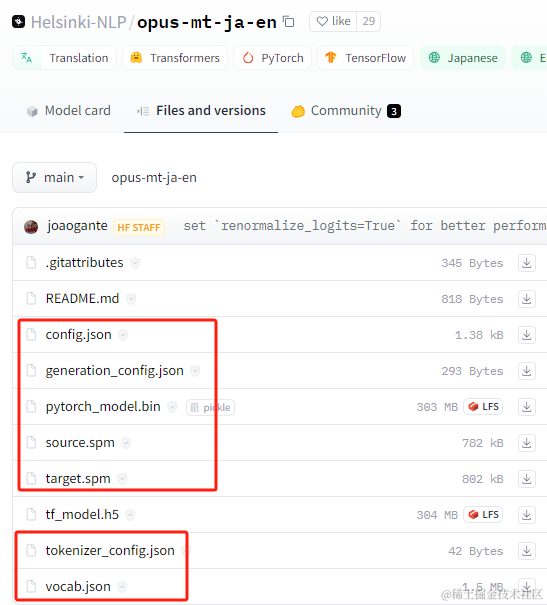
在这里找了下,没找到日转中的模型,只找到日转英,那就只能转两遍了,先日转英再英转中,只需要下载红框里的这7个文件(附:《不同语言及英文简称对照表》):
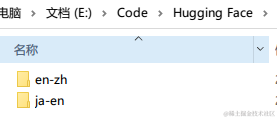
放到两个指定的本地文件夹中:
接着pip装下包:
pip install torch
pip install sacremoses
接着通过加载本地模型来实现翻译功能:
from transformers import pipeline
if __name__ == ‘__main__’:
ja_en_model_path = r”E:\Code\Hugging Face\ja-en”
ja_en_tokenizer = AutoTokenizer.from_pretrained(ja_en_model_path)
ja_en_model = AutoModelForSeq2SeqLM.from_pretrained(ja_en_model_path)
pipeline = pipeline(“translation”, model=jap_en_model, tokenizer=jap_en_tokenizer)
result = pipeline(read_file_text_content(“short.txt”))
print(result[0][‘translation_text’])
运行后报错:

原因:输入文本过长,超过了模型支持的最大长度512个token,序列过长导致index出错,解法就是对输入的文本进行分割。修改后的代码:
ja_en_model_path = r”E:\Code\HuggingFace\ja-en”
ja_en_tokenizer = AutoTokenizer.from_pretrained(ja_en_model_path)
ja_en_model = AutoModelForSeq2SeqLM.from_pretrained(ja_en_model_path)
ja_en_pipeline = pipeline(“translation”, model=ja_en_model, tokenizer=ja_en_tokenizer)
translation_content = read_file_text_content(“short.txt”)
content_length = len(translation_content)
range_index = 0
range_count = math.ceil(content_length / 512)
while True:
if range_index == range_count:
break
result = ja_en_pipeline(translation_content[512 * range_index: 512 * (range_index + 1)])
print(result[0][‘translation_text’])
range_index += 1
运行后控制台输出日转英:

接着把英转中的代码也安排上:
en_cn_tokenizer = AutoTokenizer.from_pretrained(en_cn_model_path)
en_cn_model = AutoModelForSeq2SeqLM.from_pretrained(en_cn_model_path)
en_cn_pipeline = pipeline(“translation”, model=en_cn_model, tokenizer=en_cn_tokenizer)
en_result = ja_en_pipeline(translation_content[512 * range_index: 512 * (range_index + 1)])
zh_result = en_cn_pipeline(en_result[0][‘translation_text’])
print(zh_result[0][‘translation_text’])
再次运行看看输出结果:

😲em…这翻译结果不太对啊,而且等挺久的,试试改成逐行翻译:
for translation_content in translation_content_list:
en_result = ja_en_pipeline(translation_content)
zh_result = en_cn_pipeline(en_result[0][‘translation_text’])
print(“{} === {}”.format(en_result[0][‘translation_text’], zh_result[0][‘translation_text’]))
运行看看输出结果:

比对下原字幕,直接把我整无语了,这让我想起一个中国的成语:以讹传讹,指的是:本来就不正确的话又错误地传出去,越传越错。
解决方法的话两个:找更适合的模型 或者 自己训练模型,这垃圾电脑,自己训练肯定是不可能的。只能再搜搜模型了,搜索片刻,终于找到两个日文转中文的模型:larryvrh/mt5-translation-ja_zh 和 neverLife/nllb-200-distilled-600M-ja-zh
😰 4.92G的模型让我望而却步,好在 Hugging Face 支持测试模型,输入要翻译的日文,然后点击 Compute 就会加载模型,然后进行调用测试:
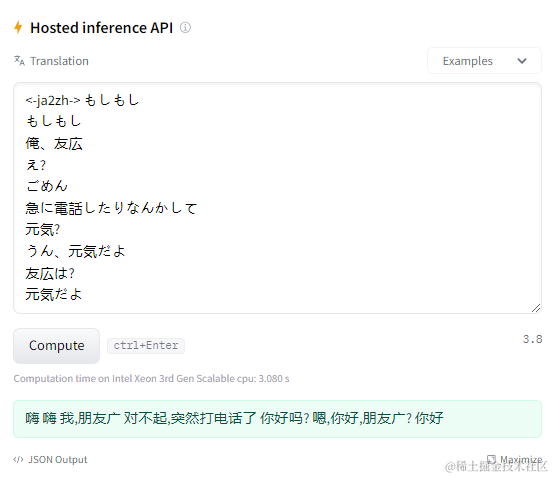
大模型就是叼,确实准确很多,不过跟我的垃圾主机无缘😭,但这种通过API调用别人模型的方式可以有~
/ OpenAI 翻译文本 /
通过API调别人训练好的模型来获取翻译结果,好处:不用自己折腾,不需要硬件资源,可以搞并发。坏处:当然是得花钱。
快速校验翻译效果的方法肯定是直接问 ChatGPT,直接写个简单的 prompt:
你是一个专业的翻译工作者,请将下面这段日文的段落翻译成中文:xxx
翻译结果如下:

卧槽,🐮牛逼,和原字幕匹配度至少有七成,如果有openai token的话,可以用python代码调用下:
openai.api_key = “sk-xxx”
response = openai.Completion.create(
engine=”text-davinci-003″,
prompt=”你是一个专业的翻译工作者,请将下面这段日文的段落翻译成中文:{}”.format(content),
temperature=1,
max_tokens=2000,
frequency_penalty=0,
presence_penalty=0
)
print(response[“choices”][0][“text”].strip())
运行结果和ChatGPT的大同小异:
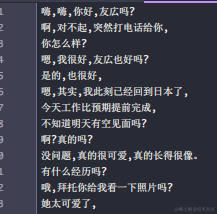
又试了下 Claude,翻译结果稍微差一点,文心一言 的话(笑死):

在视频播放的时候挂载字幕的话,需要 srt 文件(Whisper有生成),用vs之类的代码编辑器打开此文件:
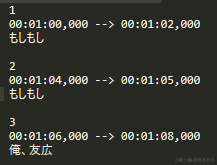
全选复制,接着换个prompt:
你是一个专业的翻译工作者,请将下面这段日文的歌词文件翻译成中文,要保留时间和序号:xxx
因为内容比较长,途中需要点几次Continue generating:
生成结果(后面还给我瞎编了一些):

挂载下字幕看看(白色字我们生成的字幕):

验证过程,也发现了Whisper生成的时间戳不太准确的问题:

这个可以问题可以用上节提到的库 jianfch/stable-ts 来改善,关于生成中文字幕的探索就记录到这啦🐍~
/ 总结 /
简单总结下,用AI生成霓虹爱情片的中文字幕的技术要点:
- ffmpeg 提取单声道wav音频
- Spleeter 提取人声
- OpenAI 将字幕翻译成中文
用到的prompt:
- 你是一个专业的翻译工作者,请将下面这段日文的段落翻译成中文:xxx
- 你是一个专业的翻译工作者,请将下面这段日文的歌词文件翻译成中文,要保留时间和序号:xxx
 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包