GPT-SoVITS 是一个基于少量语音数据(1 分钟左右)即可训练出高质量 TTS(文本转语音)模型的开源项目,提供少样本语音克隆能力。目前该开源项目已经获得了 33.2k 的 Star!
它允许用户使用 5 秒的语音样本进行零样本 TTS 转换,并支持多语言推理,包括英语、中文、日语、韩语和粤语。
① 零样本 TTS:快速输入 5 秒语音,立即进行文本转语音转换。
② 少样本 TTS:通过 1 分钟的训练数据来微调模型,实现更真实的语音转换效果。
③ 跨语言支持:支持多种语言的推理。
支持 Windows、Linux 和 macOS,可通过 Conda 或 Docker 进行安装。
开源地址:https://github.com/RVC-Boss/GPT-SoVITS
此外,项目提供了图形化 WebUI 工具,支持音频切分、自动训练集生成以及 ASR 转录等辅助工具,便于用户构建和训练自己的语音模型。
So-VITS-SVC 是一个开源的语音转换项目,其全称为 SoftVC VITS Singing Voice Conversion,专注于通过深度学习模型实现语音转换,尤其适用于歌声转换。
该项目的目标是利用训练好的深度学习模型将一种歌声转换为另一种目标歌手的声音,广泛应用于音乐创作、虚拟歌手的声音生成等领域。
🚀 应用场景
① 虚拟歌手:许多虚拟偶像和歌手项目可以通过 So-VITS-SVC 实现声音的定制化,帮助创作者打造独特的音色。
② 音乐创作:音乐人可以使用该工具将不同歌手的声音融合到新的创作中,从而扩展音乐作品的多样性。
③ 配音与语音合成:除了歌声转换,So-VITS-SVC 还可以应用于配音领域,将某个角色的声音合成另一种音色。
开源地址:https://github.com/svc-develop-team/so-vits-svc
这是一个带操作界面的声音克隆工具,目前已经在 GitHub 上获得了 7.3k 的 Star。英文合成效果非常出色,中文合成效果尚可。操作非常简便,即使没有 GPU 也能使用。
开源地址:https://github.com/jianchang512/clone-voice
只需下载预编译版本,双击 app.exe 后会打开一个网页界面,简单点击鼠标即可使用。可以使用任何人类的音色,将文字合成为该音色的语音,或者将一个声音转化为另一种音色的声音。
工具支持中文、英文、日语、韩语、法语、德语、意大利语等16种语言,并且支持通过麦克风在线录制声音。
为了确保合成效果,建议你的录音时长控制在 5 到 20 秒之间,发音要清晰准确,并避免背景噪音。
Mocking Bird 是开发者 @babysor 开源的比较火的 AI 拟声开源项目,目前在 GitHub 已经获得了 35K 的 Star,它能在 5 秒内克隆你的声音并生成任意语音内容,支持中文普通话。
开源地址:https://github.com/babysor/MockingBird
Demo视频:https://www.bilibili.com/video/BV17Q4y1B7mY
🚀 功能特性
① 支持中文普通话拟声,并且在多个中文数据集进行了测试
② 支持在 Windows、Linux、Mac 操作系统使用
③ 基于 B/S 架构交互,简单收集声音,生成拟声
④ 详细的部署教程、训练教程、使用教程
💻 部署教程
如何部署在该项目的 Readme 写的很详细,相对比较简单,按说明把 Python 环境、PyTorch、多媒体处理组件 FFmpeg 装好,剩下的就用把依赖库都装了,就差不多完成了。
部署成功后,可以在浏览器访问 8080 端口来体验 Mocking Bird。
首先输入生成语音的中文话术,然后录制一段你的声音,使用 synthesizer 或者其它模型进行训练一下,就能合成一段语音了。
简单的这几步,你会发现离以假乱真的效果还有距离。这时候就要运行开发者提供的 demo_toolbox.py 工具箱,进行调参以达到满意的效果。
Real-Time-Voice-Cloning 是一个将语音转换为文本并生成多发言者文本到语音合成(SV2TTS)模型的深度学习框架,能在几秒钟内实时生成高质量的语音克隆。目前该开源项目已经获得了 52.3k 的 Star。
开源地址:https://github.com/CorentinJ/Real-Time-Voice-Cloning
利用深度学习,通过三步完成语音克隆。首先,它会根据短短几秒钟的语音片段生成说话者的数字化语音表示。
接着,基于该表示,系统能够生成与输入语音匹配的任意文本的语音。这使得我们可以合成出无限多的句子,听起来就像是克隆源的原始发声者。
该项目的框架由三个主要模块组成:编码器、合成器 和 声码器(Vocoder)。每个模块都负责处理特定的阶段:编码器提取音频特征,合成器生成语音频谱图,声码器将频谱图转化为最终的音频。
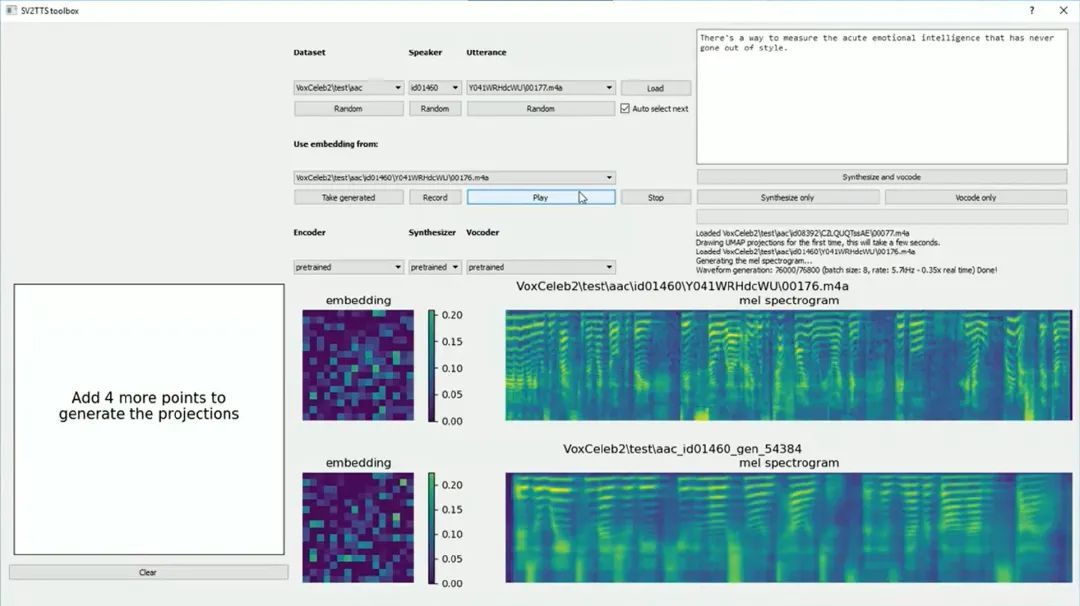
这个项目提供了 GUI 界面,交互傻瓜式操作,语音采集、训练、生成都可以交互完成,很方便。
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。侵权投诉:375170667@qq.com