本文是 Meta 官网推出的 Llama2 使用教学博客,简单 5 步教会你如何使用 Llama2。
在这篇博客中,Meta 探讨了使用 Llama 2 的五个步骤,以便使用者在自己的项目中充分利用 Llama 2 的优势。同时详细介绍 Llama 2 的关键概念、设置方法、可用资源,并提供一步步设置和运行 Llama 2 的流程。
Meta 开源的 Llama 2 包括模型权重和初始代码,参数范围从 7B 到 70B。Llama 2 的训练数据比 Llama 多了 40%,上下文长度也多一倍,并且 Llama 2 在公开的在线数据源上进行了预训练。

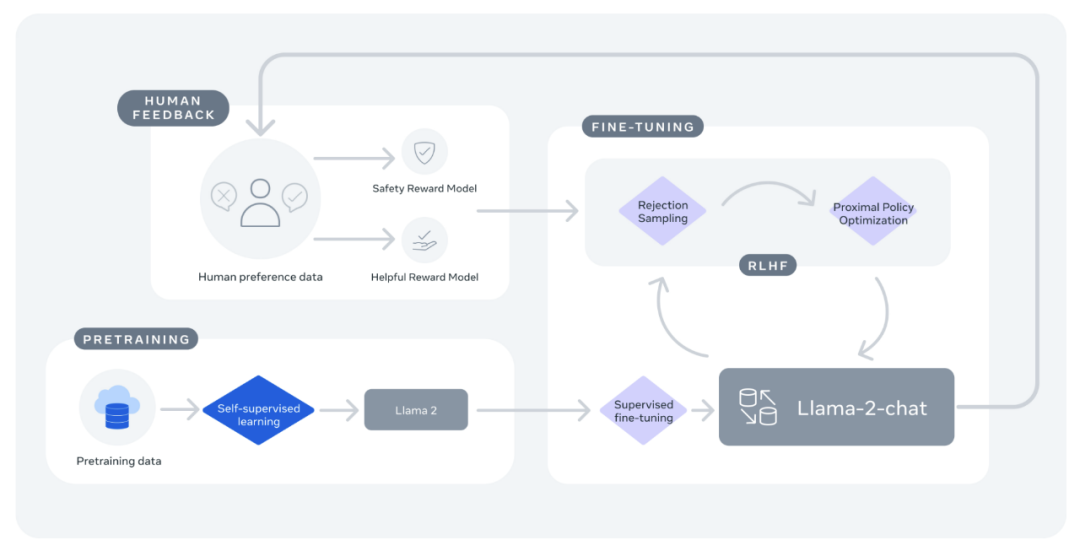
在推理、编码、熟练程度和知识测试等多项外部基准测试中,Llama 2 的表现均优于其他开放式语言模型。Llama 2 可免费用于研究和商业用途。
下一节中将介绍使用 Llama 2 的 5 个步骤。在本地设置 Llama 2 有多种方法,本文讨论其中一种方法,它能让你轻松设置并快速开始使用 Llama。
本文将使用 Python 编写脚本来设置并运行 pipeline 任务,并使用 Hugging Face 提供的 Transformer 模型和加速库。
pip install transformerspip install accelerate
本文使用的模型可在 Meta 的 Llama 2 Github 仓库中找到。通过此 Github 仓库下载模型需要完成两步:
-
访问 Meta 网站,接受许可并提交表格。请求通过后才能收到在电子邮件中的预签名 URL;
-
启动 download.sh 脚本(sh download.sh)。出现提示时,输入在电子邮件中收到的预指定 URL。
-
选择要下载的模型版本,例如 7b-chat。然后就能下载 tokenizer.model 和包含权重的 llama-2-7b-chat 目录。
运行 ln -h ./tokenizer.model ./llama-2-7b-chat/tokenizer.model,创建在下一步的转换时需要使用的 tokenizer 的链接。
转换模型权重,以便与 Hugging Face 一起运行:
TRANSFORM=`python -c"import transformers;print ('/'.join (transformers.__file__.split ('/')[:-1])+'/models/llama/convert_llama_weights_to_hf.py')"`pip install protobuf && python $TRANSFORM --input_dir ./llama-2-7b-chat --model_size 7B --output_dir ./llama-2-7b-chat-hf
Meta 在 Hugging Face 上提供了已转换的 Llama 2 权重。要使用 Hugging Face 上的下载,必须按照上述步骤申请下载,并确保使用的电子邮件地址与 Hugging Face 账户相同。
接下来创建一个 Python 脚本,该脚本将包含加载模型和使用 Transformer 运行推理所需的所有代码。
首先需要在脚本中导入以下必要模块:LlamaForCausalLM 是 Llama 2 的模型类,LlamaTokenizer 为模型准备所需的 prompt,pipeline 用于生成模型的输出,torch 用于引入 PyTorch 并指定想要使用的数据类型。
import torchimport transformersfrom transformers import LlamaForCausalLM, LlamaTokenizer
接下来,用下载好并转换完成的权重(本例中存储在 ./llama-2-7b-chat-hf 中)加载 Llama 模型。
model_dir = "./llama-2-7b-chat-hf"model = LlamaForCausalLM.from_pretrained (model_dir)
在最终使用之前确保为模型准备好输入,这可以通过加载与模型相关的 tokenizer 来实现。在脚本中添加以下内容,以便从同一模型目录初始化 tokenizer:
tokenizer = LlamaTokenizer.from_pretrained (model_dir)
接下来还需要一种方法来赋予模型推理的能力。pipeline 模块能指定 pipeline 任务运行所需的任务类型(text-generation)、推理所需的模型(model)、定义使用该模型的精度(torch.float16)、pipeline 任务运行的设备(device_map)以及其他各种配置。
在脚本中添加以下内容,以实例化用于运行示例的流水线任务:
pipeline = transformers.pipeline ("text-generation",model=model,tokenizer=tokenizer,torch_dtype=torch.float16,device_map="auto",)
在定义了 pipeline 任务后,还需要提供一些文本提示,作为 pipeline 任务运行时生成响应(序列)的输入。下面示例中的 pipeline 任务将 do_sample 设置为 True,这样就可以指定解码策略,从整个词汇表的概率分布中选择下一个 token。本文示例脚本使用的是 top_k 采样。
通过更改 max_length 可以指定希望生成响应的长度。将 num_return_sequences 参数设置为大于 1,可以生成多个输出。在脚本中添加以下内容,以提供输入以及如何运行 pipeline 任务的信息:
sequences = pipeline ('I have tomatoes, basil and cheese at home. What can I cook for dinner?\n',do_sample=True,top_k=10,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,max_length=400,)for seq in sequences:print (f"{seq ['generated_text']}")
现在,这个脚本已经可以运行了。保存脚本,回到 Conda 环境,输入
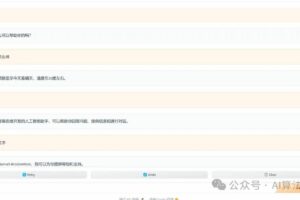
如下图所示,开始下载模型,显示 pipeline 任务的进展,以及输入的问题和运行脚本后生成的答案:
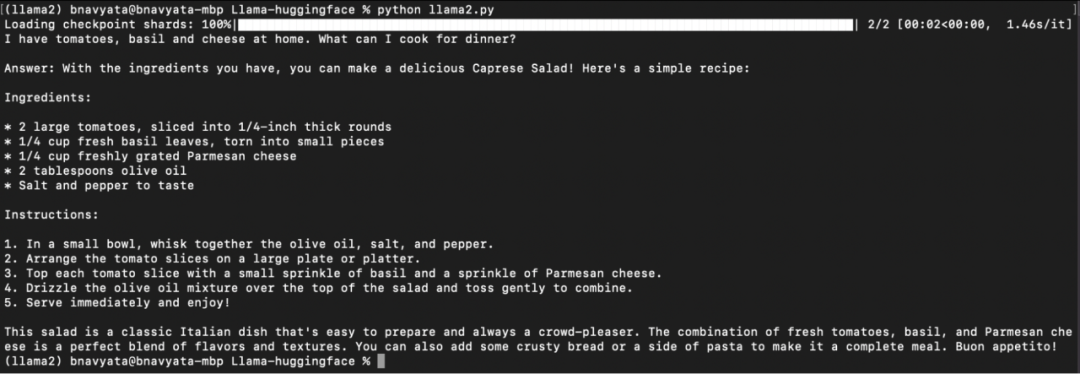
现在可以在本地设置并运行 Llama 2。通过在字符串参数中提供不同的提示来尝试不同的提示。你还可以通过在加载模型时指定模型名称来加载其他 Llama 2 模型。下一节中提到的其他资源可以帮你了解更多 Llama 2 工作原理的信息,以及可用于帮助入门的各种资源。
要了解有关 Llama 2 工作原理、训练方法和所用硬件的更多信息,请参阅 Meta 的论文《Llama 2: Open Foundation and Fine-Tuned Chat Models》,其中对这些方面进行了更详细的介绍。
论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
从 Meta 的 Llama 2 Github repo 获取模型源代码,源代码展示了模型的工作原理以及如何加载 Llama 2 模型和运行推理的最简单示例。在这里还可以找到下载、设置模型的步骤以及运行文本补全和聊天模型的示例。
repo 地址:https://github.com/facebookresearch/llama
在模型卡片(中了解模型的更多信息,包括模型架构、预期用途、硬件和软件要求、训练数据、结果和许可证。
卡片地址:https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
在 Meta 的 llama-recipes Github repo 中提供了如何快速开始微调以及如何为微调模型运行推理的示例。
repo 地址:https://github.com/facebookresearch/llama-recipes/
查阅 Meta 最近发布的编码人工智能工具 Code Llama,这是一个建立在 Llama 2 基础上的人工智能模型,针对生成和分析代码的能力进行了微调。
Code Llama 地址:https://about.fb.com/news/2023/08/code-llama-ai-for-coding/
阅读《负责任使用指南》,它提供了以负责任的方式构建由大语言模型 (LLM) 支持的产品的最佳实践和注意事项,涵盖了从开始到部署的各个开发阶段。
指南地址:https://ai.meta.com/llama/responsible-use-guide/
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。侵权投诉:375170667@qq.com