llama2获取模型参数并且hf化
由于LLaMA权重的许可限制,该模型不能用于商业用途,请严格遵守LLaMA的使用政策。考虑到LLaMA权重的许可证限制,我们无法直接发布完整的模型权重。因此,我们使用了FastChat开源工具作为基础,并对其进行了进一步的优化。我们计算并发布了Ziya-LLaMA-13B-v1权重与原始LLaMA权重之间的差值。用户可以按照以下步骤操作以获得Ziya-LLaMA-13B-v1完整权重,具体步骤如下:
步骤一:下载llama2模型
首先我们需要登入llama2的官方网站
https://ai.meta.com/llama/点击下载按钮,进入下载界面
接下来我们会进入这样的一个界面需要我们填写一些信息,申请资格:

几乎很快就会收到同意的消息,
输入信息之后打开我们填写的邮箱:获取对应的链接:
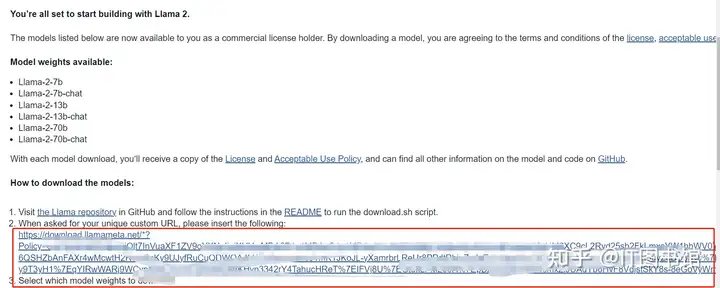
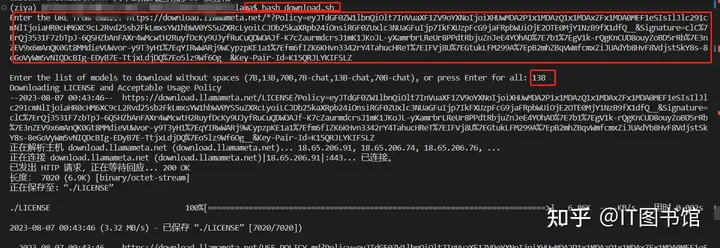
在官网的llama中有一个download.sh 的脚本,运行这个脚本,粘贴这个下载的链接,输入我们需要下载的版本号,就可以下载模型啦~
步骤二:模型hf化
原始的LLaMA权重文件,是不能直接调用huggingface的transformers库进行使用的。如果要使用huggingface transformer训练LLaMA,需要使用额外的转换脚本(具体详见huggingface官网指南),把上述的LLaMa-xx进行额外的转换;或者使用上述已经被转换好的LLaMA-xx-hf.
由于LLaMA权重的许可限制,该模型不能用于商业用途,请严格遵守LLaMA的使用政策。考虑到LLaMA权重的许可证限制,我们无法直接发布完整的模型权重。因此,我们使用了FastChat开源工具作为基础,并对其进行了进一步的优化。我们计算并发布了Ziya-LLaMA-13B-v1权重与原始LLaMA权重之间的差值。用户可以按照以下步骤操作以获得Ziya-LLaMA-13B-v1完整权重,具体步骤如下:
Step 1:获取LLaMA权重并转成Hugging Face Transformers模型格式,可参考转换脚本(若已经有huggingface权重则跳过)在这里请使用 transformers提供的脚本convert_llama_weights_to_hf.py,
将原版LLaMA模型转换为HuggingFace格式。
将原版LLaMA的tokenizer model放在--input_dir指定的目录,其余文件放在${input_dir}/${model_size}下。
执行以下脚本(注意这个脚本路径指的是transformers的路径,不是本项目的目录)后,--output_dir中将存放转换好的HF版权重。
【我个人的理解是需要把Tokenizer、model、generation这三个文件放在input_dir中,然后下面有个13B的文件夹存放其余的文件】
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights
--model_size 13B
--output_dir /output/path这里需要解析一下 convert_llama_weights_to_hf.py 这个脚本
这个脚本是用来将LLaMA模型(EleutherAI开发的大型自然语言处理模型)的权重转换为Hugging Face transformers库可以使用的形式。整体的运行流程大概如下:
1. 解析输入参数,这些参数包括模型的大小(对应的是模型参数的数量),输入目录(包含LLaMA模型的权重和tokenizer的数据),输出目录(将转换后的模型保存到的位置),以及安全序列化选项。
2. 在主函数中,根据解析到的参数调用`write_model`函数。该函数将从输入目录中加载LLaMA模型的权重,并进行转换,最后保存到输出目录中。
3. 在`write_model`函数中,根据模型的大小读取对应的参数,这些参数包括层数,头数,维度等。然后根据模型是否分片进行不同的处理。对于未分片的模型,直接加载模型权重并转换成适应Hugging Face的形式。对于分片的模型,加载每个片段,对参数进行重新组织并转换成适应Hugging Face的形式。
4. 在转换完成后,`write_model`函数会将转换后的模型参数保存到一个临时的目录,并将模型的配置信息保存到一个JSON文件中。然后加载这个模型,进行测试,如果测试通过,那么就将模型保存到输出目录中。
5. 在主函数中,调用`write_tokenizer`函数。这个函数会从输入目录中加载tokenizer的数据,并保存到输出目录中。
总的来说,这个脚本的主要功能是将LLaMA模型的权重转换为适合Hugging Face transformers库使用的形式,并保存下来。这样一来,你就可以使用Hugging Face transformers库来加载和使用这个模型了。
后来我发现在huggingface上好像更新了hf的版本,直接git+clone就可以啦~
不过要注意输入密钥,流程在这里:
获取 Hugging Face 的 API 令牌(Token)的步骤如下:
访问 Hugging Face 的网站,并点击右上角的 “Sign In” 按钮登录您的账户。
登录后,点击您的用户名进入您的个人主页。
在您的个人主页上,点击右侧的 “Settings” 按钮。
在 “Settings” 页面中,您将看到一个名为 “API Tokens” 的部分。
在这里,您应该能看到一个名为 “API Token” 的字段,旁边有一串字符,这就是您的 API 令牌。
复制这个令牌,并将其粘贴到您的环境变量设置命令中,例如:export HUGGINGFACE_TOKEN=your_token_here
请注意,这个 API 令牌需要妥善保管,不要泄露给他人,因为拥有这个令牌的人将能够以您的身份访问 Hugging Face。
Step 2:下载Ziya-LLaMA-13B-v1的delta权重以及step 1中转换好的原始LLaMA权重,使用如下脚本转换:https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/utils/apply_delta.py
python3 -m apply_delta --base ~/model_weights/llama-13b --target ~/model_weights/Ziya-LLaMA-13B --delta ~/model_weights/Ziya-LLaMA-13B-v1Step 3: 加载step 2得到的模型推理
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
ckpt = '基于delta参数合并后的完整模型权重'
query="帮我写一份去西安的旅游计划"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt, use_fast=False)
inputs = '<human>:' + query.strip() + '\n<bot>:'
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)单LoRA权重合并(适用于 Chinese-LLaMA, Chinese-LLaMA-Plus, Chinese-Alpaca)
执行以下命令:
python scripts/merge_llama_with_chinese_lora.py \
--base_model path_to_original_llama_hf_dir \
--lora_model path_to_chinese_llama_or_alpaca_lora \
--output_type [pth|huggingface] \
--output_dir path_to_output_dir 参数说明:
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录(Step 1生成)--lora_model:中文LLaMA/Alpaca LoRA解压后文件所在目录,也可使用 Model Hub模型调用名称--output_type: 指定输出格式,可为pth或huggingface。若不指定,默认为pth--output_dir:指定保存全量模型权重的目录,默认为./- (可选)
--offload_dir(仅对旧脚本scripts/merge_llama_with_chinese_lora.py有效): 对于低内存用户需要指定一个offload缓存路径 - (可选)
--verbose(仅对新脚本scripts/merge_llama_with_chinese_lora_low_mem.py有效):显示合并过程中的详细信息
多LoRA权重合并(适用于Chinese-Alpaca-Plus)
合并Chinese-Alpaca-Plus需要提供两个LoRA权重,分别为Chinese-LLaMA-Plus-LoRA和Chinese-Alpaca-Plus-LoRA。执行以下命令完成合并:
python scripts/merge_llama_with_chinese_lora.py \
--base_model path_to_original_llama_hf_dir \
--lora_model path_to_chinese_llama_plus_lora,path_to_chinese_alpaca_plus_lora \
--output_type [pth|huggingface] \
--output_dir path_to_output_dir 参数选项含义与单LoRA权重合并中的含义相同。需要注意的是 --lora_model参数后要提供两个lora_model的地址,用逗号分隔。⚠️ 两个LoRA模型的顺序很重要,不能颠倒。先写LLaMA-Plus-LoRA然后写Alpaca-Plus-LoRA。
Step 3: 合并后检查(重要!)
合并完成后务必检查SHA256!合并完成后务必检查SHA256!合并完成后务必检查SHA256!
- 合并后pth文件的SHA256:Chinese-LLaMA-Alpaca/SHA256.md at main · ymcui/Chinese-LLaMA-Alpaca · GitHub
- 推荐先转成pth格式,比对SHA256无误后,如有需要再转成HF格式,因为HF格式对应的模型SHA256经常发生变化(meta信息改变)
- 另外,也可参考我们的解码示例,使用相同的解码参数进行测试。如果多次运行后结果与示例相差较大,则可能表示合并后的模型可能存在不完整等问题。强烈建议比对以上SHA256值,确保模型正确。
注意:这里有一个更加详细的说法:
2. 模型部署
首先说明一下项目的文件系统目录
-llama-13B
-llama-13B-convert
-ziya_v1.1_delta
-ziya_v1.1
-apply_delta.py
-convert_llama_weights_to_hf.py
-launch.py
-utils.py其中llama-13B为llama原始参数存放的目录,llama-13B-convert为转换成huggingface形式的参数存放的目录,ziya_v1.1_delta为huggingface上的权重文件,ziya_v1.1为最终转换后的权重文件。launch.py为本地化部署文件,详见后续章节,utils.py为官方给的文件,直接从https://modelscope.cn/studios/Fengshenbang/Ziya_LLaMA_13B_v1_online/files下载即可。
2.1 llama-13B权重转换
首先第一步需要将llama-13B的原始权重转换成huggingface的权重形式,使用convert_llama_weights_to_hf.py脚本进行转换,转换代码如下:
python convert_llama_weights_to_hf.py --input_dir $你的llama-13B路径 --model_size 13B --output_dir $你的llama-13B模型转换后的路径2.2 结合基础的llama权重和Ziya-LLaMA-13B delta权重得到Ziya-LLaMA-13B权重
使用如下代码得到最终的Ziya-LLaMA-13B权重。
python -m apply_delta --base $你的llama-13B模型转换后的路径 --target $你的最终权重存储路径 --delta $你下载的Ziya-LLaMA-13B权重路径部分内容来自于:https://github.com/ChaosWang666/Ziya-LLaMA-13B-deployment
反正跟着教程一顿操作最后也跑通啦~~~
补充:
对于第二部分的文件夹内容可能还存在一些问题这里进行一下补充:
在llama-13B权重转换的过程中:
这里面我们需要准备的是一个叫llama的文件夹,把llama-2-13b的名字改成13B放在文件夹下,同时把原始llama中一个叫tokenizer.model的模型放在里面,这里结构如图,13B是改名的llama-2-13b,tokenizer.model是复制过来的,然后运行:
python convert_llama_weights_to_hf.py
--input_dir /ziya-llama/llama
--model_size 13B
--output_dir /ziya-llama/llama-13B-convert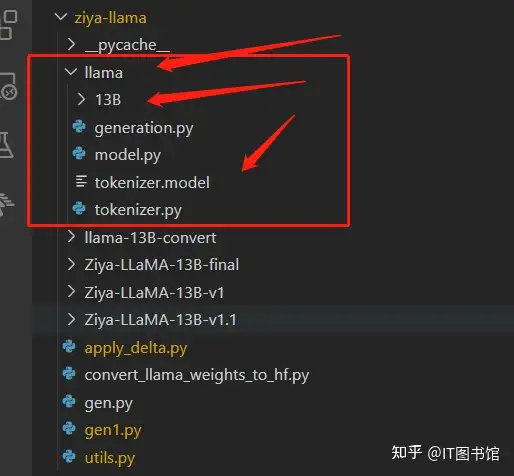
然后我们需要进行结合基础的llama权重和Ziya-LLaMA-13B delta权重得到Ziya-LLaMA-13B权重
python -m apply_delta --base
$你的llama-13B模型转换后的路径
--target $你的最终权重存储路径
--delta $你下载的Ziya-LLaMA-13B权重路径这里比如可以这样写:
python -m apply_delta
--base /ziya-llama/llama-13B-convert
--target /ziya-llama/Ziya-LLaMA-13B-final
--delta /ziya-llama/Ziya-LLaMA-13B-v1.1结果存储在Ziya-LLaMA-13B-final 中
扫码领红包 微信赞赏
微信赞赏 支付宝扫码领红包
支付宝扫码领红包